Daily Trend [11-22]
【1】Learning Unsupervised World Models for Autonomous Driving via Discrete Diffusion
【URL】https://arxiv.org/abs/2311.01017v1
【Time】2023-11-02
一、研究领域
世界模型,离散扩散模型,自动驾驶
二、研究动机
学习 world model 可以以无监督的方式教会 agent 世界是如何运作的。但是两个瓶颈阻碍了这个领域的发展:
(1)dealing with complex and unstructured observation space
(2)having a scalable generative model
因此,作者提出了一种新颖的世界建模方法,首先使用 VQVAE 对传感器观测进行 tokenizing ,然后通过离散扩散预测未来。
三、方法与技术
(1)Overview:把 agent experience 建模为 o,a 序列(o 是 point cloud observation,a 是 action) ,目标是学习一个 world model,根据以往的 o,a 序列预测下一个 o,这个 world model 由离散扩散模型实现。
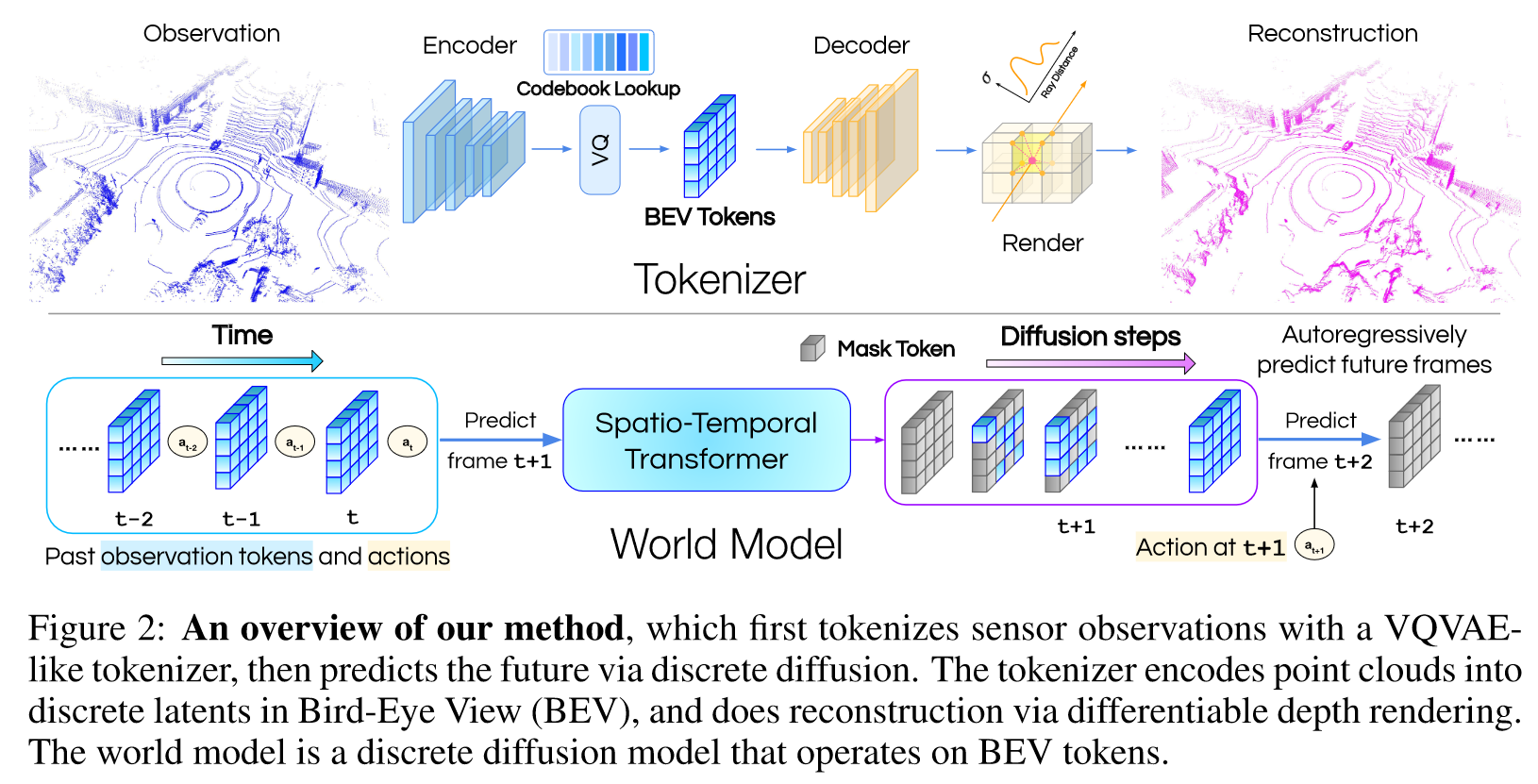
(2)TOKENIZE THE 3D WORLD:encoder 结构包含 PointNet,BEV 和 Swin Transformer,通过 VQ 获得 token;decoder 结构包含几个 Swin Transformer Blocks 和 两个输出分支,第一个分支使用隐式表示,以便查询连续坐标处的 occupancy,第二个分支通过预测体素的输入中是否有 points 来学习点云的粗略重建。这个 tokenizer 的损失函数是矢量量化损失 Lvq 和渲染损失 Lrender 的组合。
(3)MASKGIT AS A DISCRETE DIFFUSION MODEL:将 MaskGIT 重构为离散扩散模型。
(4)LEARNING A WORLD MODEL:作者认为训练世界模型应该超越 next observation prediction 的模式,根据过去的情况预测 an entire segment of future observations。因此,将世界模型设计为类似于 BERT 的时空版本,在时间维度上进行因果屏蔽。未来的预测是通过掩蔽、填充和进一步去噪来完成的。该模型采用混合目标和混合 condition 进行训练:

四、总结
网络的结构性设计非常非常富有经验,混合目标训练的策略也很有意思,但是训练过程应该很复杂。
五、推荐相关阅读
Maskgit: Masked generative image transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 11315–11325, 2022.