Daily Trend [11-23]
【1】Video-LLaVA: Learning United Visual Representation by Alignment Before Projection
【URL】http://arxiv.org/abs/2311.10122
【Time】2023-11-16
一、研究领域
Large Vision-Language Model (LVLM),图像/视频理解。
二、研究动机
目前大多数 LVLM 只能处理单一的视觉模态,而类似于 ImageBind/LanguageBind 的方法又会由于间接对齐而导致性能变差,所以作者提出 Video-LLaVA 将图像和视频模态直接对齐到统一的视觉特征表示和语言特征空间。
三、方法与技术
(1)Overview:先使用预训练的 LanguageBind Encoder 将 Image 和 Video 映射到和文本对齐的特征空间,获得统一的视觉表示,然后和 LLM 共同训练一个 Share Projection Layers 模块来 encode 这个统一的视觉表示。

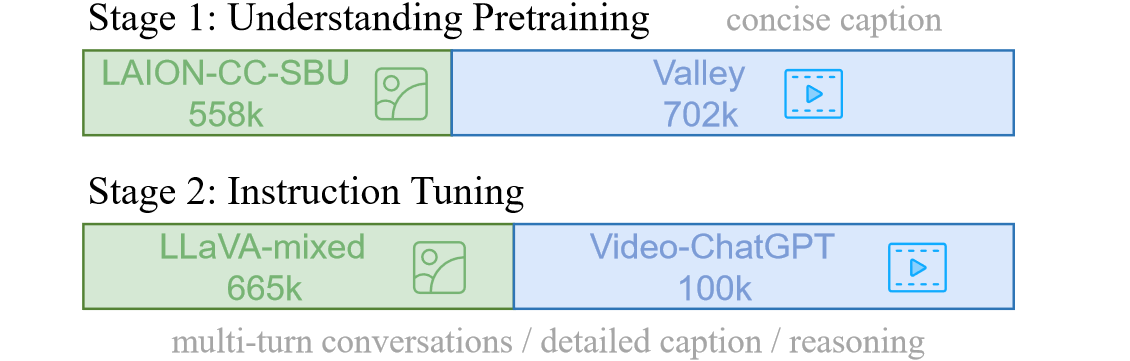
(2)训练过程:对图像和视频进行联合训练(因为认为对image和对video的理解能力学习可以相互促进),分两个阶段进行。第一个阶段是 Understanding Training,侧重于简洁的视觉描述,仅使用和视觉信号对应的单轮对话数据和原始的自回归损失训练;第二个阶段是 Instruction Tuning,强调复杂的视觉推理,把和视觉信号对应的多轮对话数据和当前的 instruction 拼接起来进行训练,训练目标和前一个阶段相同。
四、总结
感觉设计上并不是很 promissing,感觉大部分能力来自于预训练的 languagebind 而不是 share projection,并没有摆脱 languagebind 间接对齐带来的信息损失,但是效果看起来很好,可能最大的贡献还是在工程实现或者数据的设计上。
五、推荐相关阅读
LanguageBind: Extending Video-Language Pretraining to N-modality by Language-based Semantic Alignment