Daily Trend [01-08]
【1】VideoPoet: A Large Language Model for Zero-Shot Video Generation
【URL】http://arxiv.org/abs/2312.14125
【Time】2023-12-21
一、研究领域
视频生成,预训练大模型,MLLM
二、研究动机
研究一种利用大语言模型进行视频生成的有效方法。希望该模型可用作多功能多任务视频生成模型,例如文本到视频、图像到视频、视频编辑和视频到视频风格化。
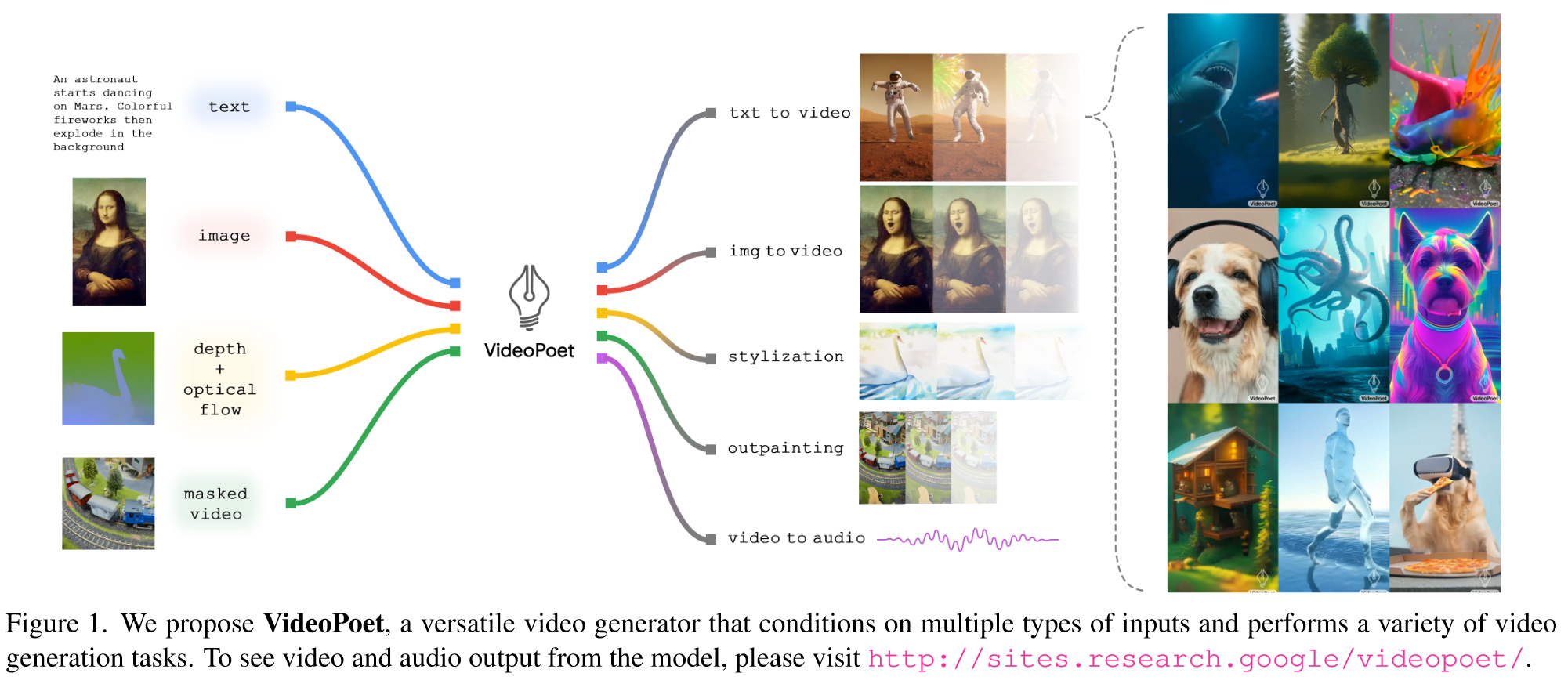
三、方法与技术
Pipeline Design
(1) modality-specific tokenizers:将输入数据(即图像像素、视频帧和音频波形)映射到统一词汇表中的离散标记。
(2) a language model backbone:接受图像、视频和音频以及文本 tokens 作为输入,并负责生成多任务和多模式建模。具体而言,VideoPoet 以文本嵌入、视觉标记和音频标记为条件,并自回归预测视觉和音频标记。
(3) a super-resolution module:超分辨率模块负责提高视频输出的分辨率,同时细化视觉细节以获得更高的质量。
Implementation Details
(1) modality-specific tokenizers:对于图像和视频,使用 MAGVIT-v2 Tokenizer 标记化,特别地单独标记每个视频的第一帧以获得更紧凑的特征和提供更丰富的信息。对于音频,使用 SoundStream 标记化。对于文本,不是直接将文本 tokens 输入到模型中,而是首先将标记输入到冻结的预训练 T5 XL 编码器中以生成文本 emebddings 序列。对于文本引导的任务,例如文本到视频,T5 XL embeddings 通过线性层投影到 Transformer 的嵌入空间中。
(2) a language model backbone:一个 Decoder-Only 架构的模型(遵循 LLM 的范式)。
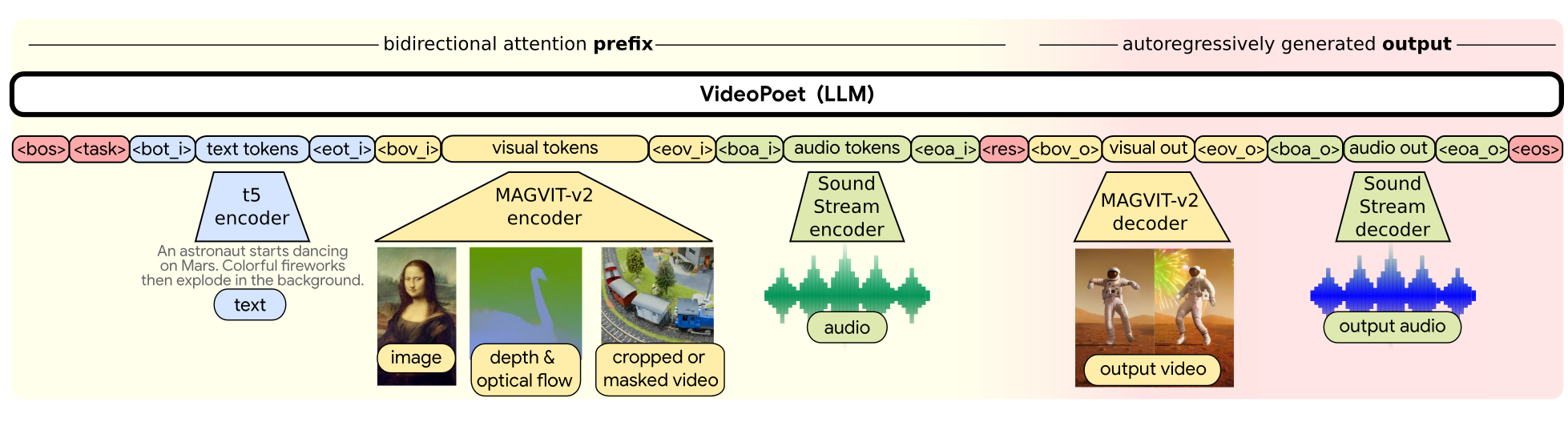
Sequence layout for VideoPoet. 其中模态不可知标记为深红色;与文本相关的组件为蓝色;与视觉相关的组件为黄色;音频相关组件呈绿色。浅黄色布局的左侧部分表示双向前缀输入。深红色的右侧部分代表具有因果注意力的自回归生成的输出。
(3) a super-resolution module:由于序列长度的增加,使用自回归转换器生成高分辨率视频会产生大量计算成本,使得自回归采样非常不切实际。因此设计了一个用于 SR 的非自回归视频转换器,结合了窗口局部注意力,具体由三个 transformer layers 组成,每个层在与 3 个轴之一对齐的局部窗口中执行自注意力:空间垂直轴、空间水平轴和时间轴。交叉注意力层关注低分辨率(LR)标记序列,并且也被划分为局部窗口,与自注意力层的窗口同构。所有块还包括对来自冻结 T5 XL 编码器的文本嵌入的交叉关注。使用两个 2× 阶段的级联从 VideoPoet 的 224 × 128 样本超分到 896 × 512 分辨率的视频。
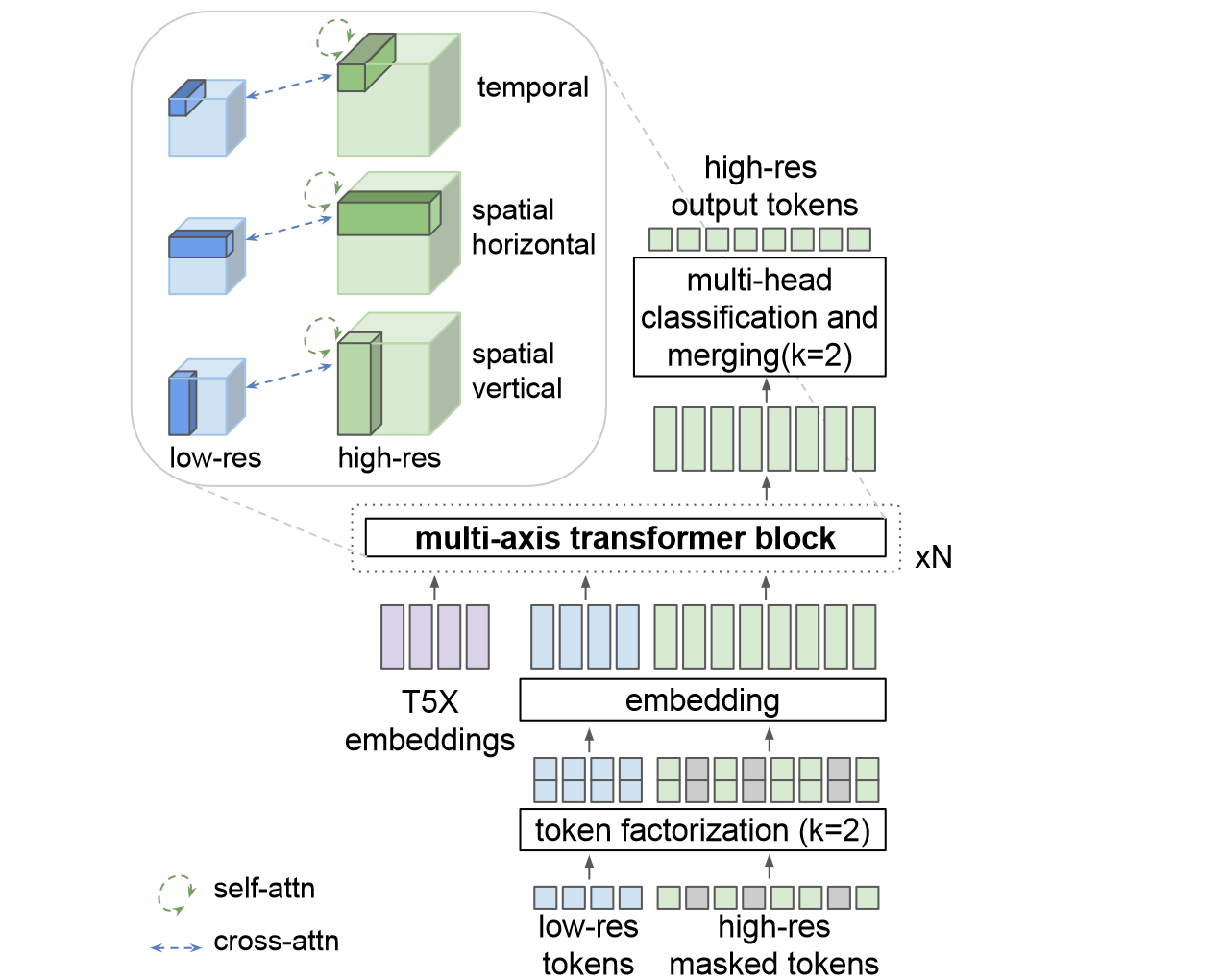
Architecture for video super-resolution. We adopt multi-axis attention and masked video modeling, conditioned on low-resolution tokens and text embeddings.
数据集
使用了来自公共互联网和其他来源的总共 1B 个图像文本对和约 2.7 亿个视频(其中超过 1 亿个包含配对文本)进行训练。数据经过过滤,删除了不良内容,并进行了采样,以改善 contextual and demographic diversity。
四、总结
VideoPoet 强调了在离散视觉和音频标记上训练的大型语言模型在生成引人注目的、最先进质量的视频方面的潜力。预训练的 VideoPoet 模型擅长多任务视频创建,可以作为各种视频相关功能(包括多种形式的编辑)的基础。希望有类似工作可以开源~