Daily Trend [12-15]
【1】MVDream: Multi-view Diffusion for 3D Generation
【URL】http://arxiv.org/abs/2308.16512
【Time】2023-08-31
一、研究领域
3D 生成
二、研究动机
提升分数蒸馏方法(利用 pretrained 2D diffusion 生成 3D assets)的 3D 一致性,克服 Multi-face Janus 问题(左)和 Content Drifting 问题(右):

左:“A bald eagle carved out of wood”,鹰有两张脸。右:“a DSLR photo of a plate of fried chicken and waffles with maple syrup on them”,鸡肉逐渐变成了华夫饼。
作者首先分析了最近的 related works(分别在3D和video生成领域),提出两个假设:
(1)即使是完美的相机条件模型也不足以解决问题,不同视图中的内容仍然可能不匹配。(例如,一只鹰可能会从前视图看向前方,同时从后视图看向右侧,其中只有它的身体符合相机条件。)
(2)3D 生成任务的几何一致性比 video 生成任务的时序一致性更 delicate,并且具有不同的扩散先验(静态场景vs动态场景)
于是提出观点:为 3D 生成任务直接训练一个 multi-view diffusion prior 非常重要,可以利用 3D Dataset 训练一个 multiview diffusion生成静态场景并访问精确的相机参数。
With such observations, we found it important to directly train a multi-view diffusion prior for the 3D generation task, where we could utilize 3D rendered dataset to generate static scenes and have access to precise camera parameters.
三、方法与技术
Insight & Problems
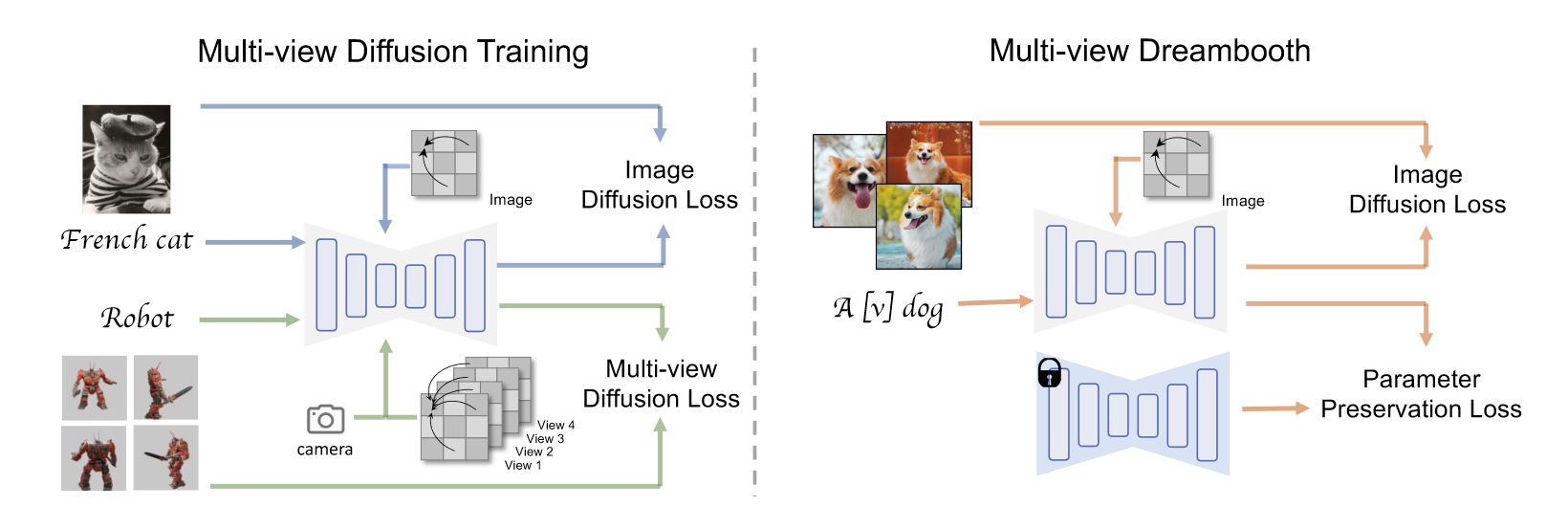
利用 3D 数据集渲染一致的多视图图像来监督扩散模型训练(每组 F 个)。为了继承文本到图像模型的通用性,所以希望尽可能保留 2D 先验模型的架构,并在 text-to-mulitiview 任务上对其进行 finetune。然而,原始的文本到图像模型一次只能生成一张图像,并且不将相机条件作为输入。因此出现三个难点:
(1)如何从相同的文本提示生成一组 consist 的多视角图像
(2)如何将 camera pose condition 添加到文本到图像模型中
(3)如何保持原始扩散模型的 quality 和 generalizability

Insight 概念图
Solution
(1)通过将原始 2D 自注意力层修改为 3D 注意力,帮助网络学习多视图一致性并且生成 consist 的图像(即使是在视角间隔非常大的情况下)。此外,修改比合并更容易训练/微调收敛。
(2)使用精确的相机外参矩阵embedding(带两层MLP)作为条件,具体实现为将其作为残差连接到time embedding里,防止其与text语义纠缠,并且帮助精确区分不同视图。
(3)为了保持原始扩散模型的 quality 和 generalizability,除了使用真实的3D渲染数据,还有几个至关重要的因素:

为了减小训练难度,在视角的选择上,均匀采样在相同仰角处分布的不同视点;视图数量F仅设置为4;遵循zero123的设定将分辨率设置为256x256;以sd2.1base为基座模型进行微调,以30%概率丢弃条件(3D注意力和camera pose condition),从而联合训练模型的多视角生成能力和保留原始的t2i能力。
Pipeline
预训练:按上述方式在Objaverse数据集上训练这样一个multi-view diffusion model。其通过控制不同的camera pose,能够生成具有多视角一致性的相应视角图片。
推理(NeRF优化):对于text-to-3D生成,在text prompt中仅使用原始文本(不像大部分工作一样附加view text),使用预训练的multi-view diffusion model生成multiview priors,用SDS Loss和一些其它的正则化损失来优化NeRF。对于image-to-3D生成,先用dreambooth做inversion,然后用这样调整后的模型做SDS优化NeRF。
四、总结
试过,非常赞,在一致性问题上暴杀其它开源工作。(个人体验)