Daily Trend [11-15]
【1】LRM: Large Reconstruction Model for Single Image to 3D
【URL】http://arxiv.org/abs/2311.04400
【Time】2023-11-07
一、研究领域
image-to-3D
二、研究动机
直接从数据集预测NeRF。利用大规模训练得到的强大3D先验,5秒就可以从单张图片生成3D模型。
”In light of this, we pose the same question for 3D: given sufficient 3D data and a large-scale training framework, is it possible to learn a generic 3D prior for reconstructing an object from a single image?“
三、方法与技术
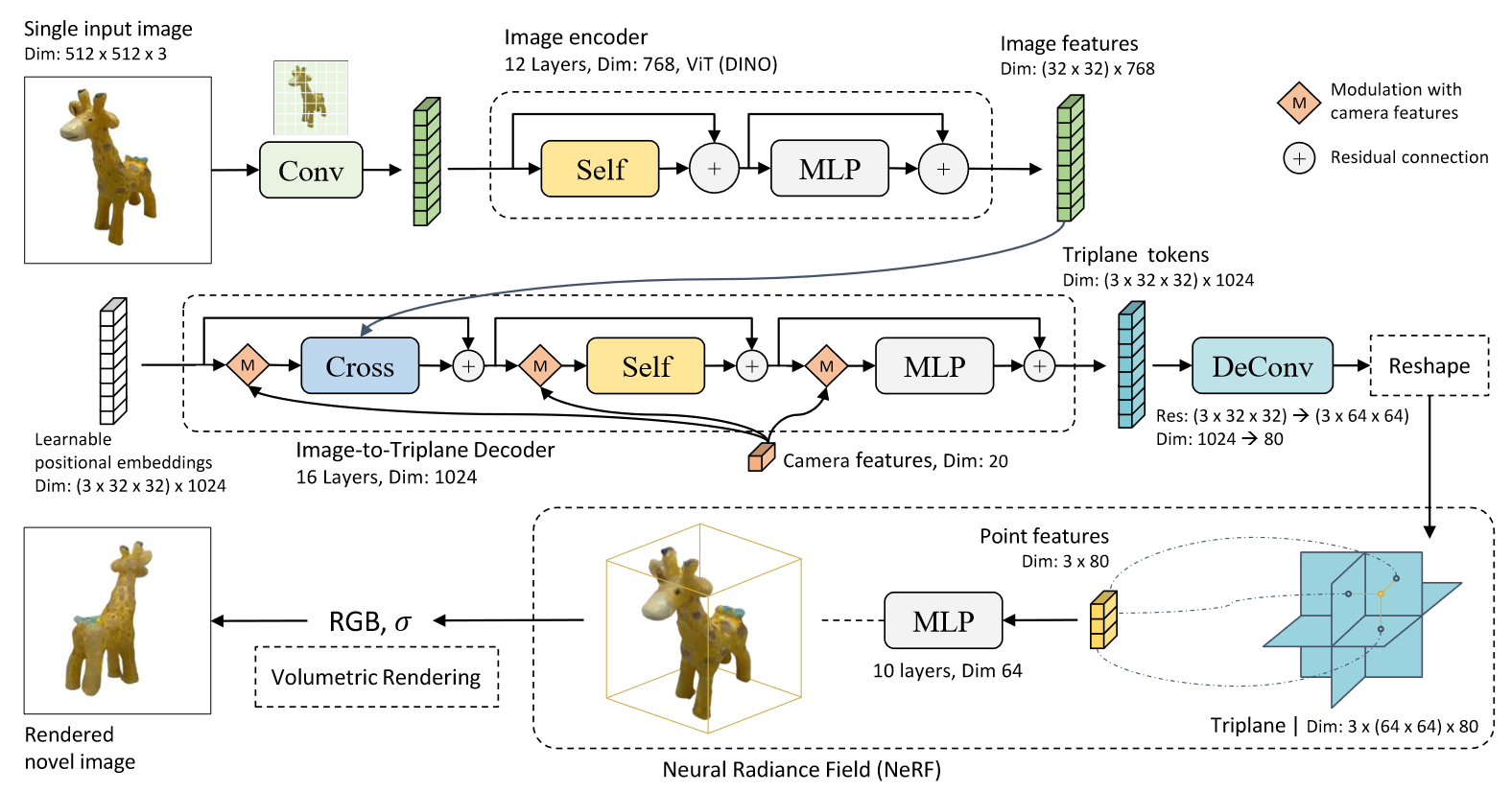
包含三个组件:
(1)Image Encoder:先用预训练的VIT把image变成tokens,然后用DINO提取feature sequence。
(2)Image-to-Triplane Decoder:将image feature和camera feature投影到可学习的positional embeddings上,然后以它们为condition,学习重建triplane representation。非常多的归一化技术细节,工程性上要非常匹配三平面的性质。
(3)multi-layer Perception:用transformer实现,每次输出的triplane representation将成为下一个transformer layer的输入。
四、总结
很暴力的方案,试图借鉴大型LLM的设计,至于为什么使用这种结构,大概意思是“maintains a high-dimensional representation across the attention layers instead of projecting the input to a latent bottleneck”。用了128块A100和1 million多视图数据,模型总参数量500 million左右。总之观望一下。