Daily Trend [11-03]
【1】FreeNoise: Tuning-Free Longer Video Diffusion via Noise Rescheduling
【URL】http://arxiv.org/abs/2310.15169
【Time】2023-10-27
一、研究领域
video generation
二、研究动机
提升视频生成的视觉连贯性,设计一种tuning-free的方法帮助长视频的生成(因为现在的视频生成模型训练基本上只能够做到短视频监督,所以生成的长视频连贯性和一致性都会比较差)。
三、方法与技术
问题定位:给定一个在具有固定数量的 Ntrain 帧的视频上进行预训练的 VideoLDM,目标是通过利用它进行推理来生成更长的视频(例如,M 帧,其中 M > Ntrain),而不会影响质量。要求是生成的 M 个视频帧语义准确且时间上连贯。
推理范式:
(1)Local Noise Shuffle Unit:假设要生成 M 帧的video,先用 N 帧的噪声来初始化,并且用随机从这 N 帧噪声中取随机打乱顺序的 S 帧来逐 S 帧初始化之后的 M - N 帧。
(2)Window based Attention Fusion:控制 temporal attention 的范围,不去注意所有帧,而是限制注意力窗口大小在 N 帧,滑动窗口大小限制为 S(即之前的洗牌单元大小,由此保证每个滑动窗口正好覆盖 N 个独立且同分布噪声的帧)。融合 attention weight 的时候不是直接取均值而是因以时间平滑的方式融合基于窗口的输出,即以距每个窗口中心的帧索引距离作为权重来计算加权和。
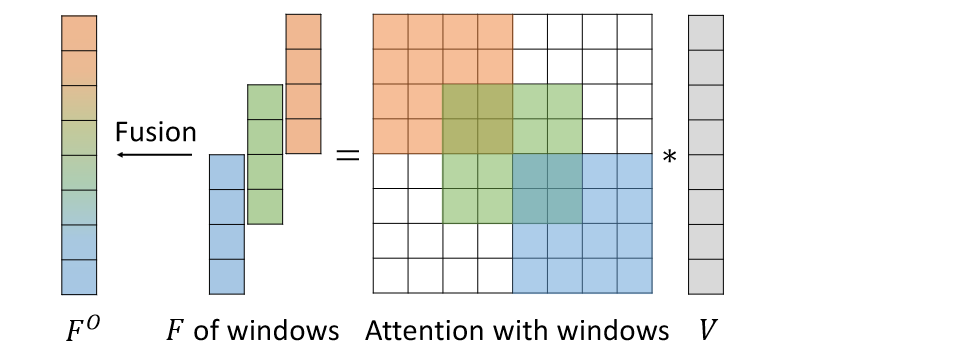
此外,比较工程性的 trick 是注入 motion 相关的 prompt:在大多数去噪步骤中使用第一个提示生成整个视频(与场景布局和外观更相关),并仅在某些特定步骤中使用目标提示(与对象形状和姿势更相关)。
四、总结
滑动窗口独立同分布采样以增加(时间)远程相关性的思想很值得借鉴。