Daily Trend [11-01]
【1】VideoCrafter1: Open Diffusion Models for High-Quality Video Generation
【URL】http://arxiv.org/abs/2310.19512
【Time】2023-10-30
一、研究领域
Video generation
二、研究动机
两种用于高质量视频生成的扩散模型,即文本到视频(T2V)和图像到视频(I2V)模型。
三、方法与技术
主要包括两个组件:LVDM 和 Video VAE
(1)Video VAE:直接逐帧使用 stable diffusion 预训练的VAE,而不考虑时序信息
(2)LVDM(Latent Video Diffusion Model):3D UNET(cond on text)
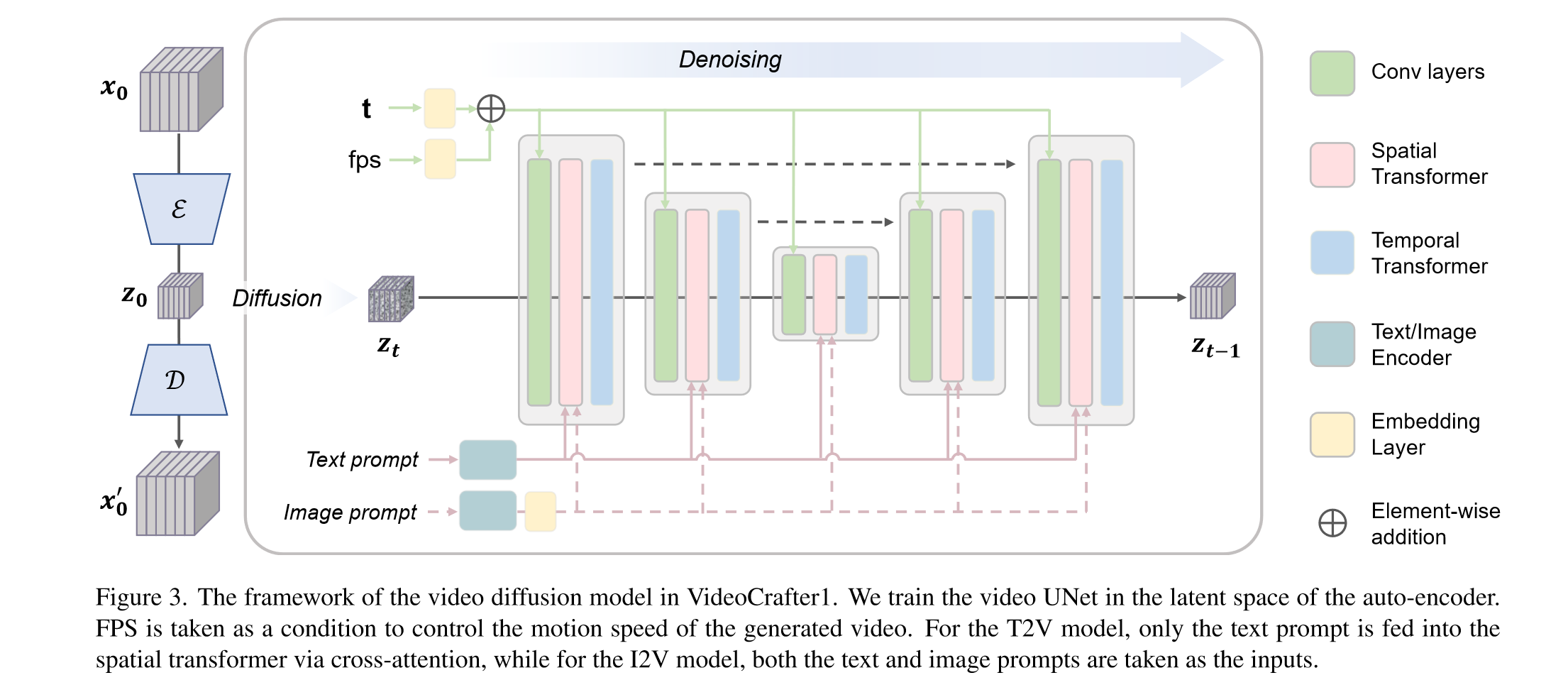
特别地,对于image2video任务,用类似于IP-adapter的方式将image embedding和text做了alignment然后作为condition:
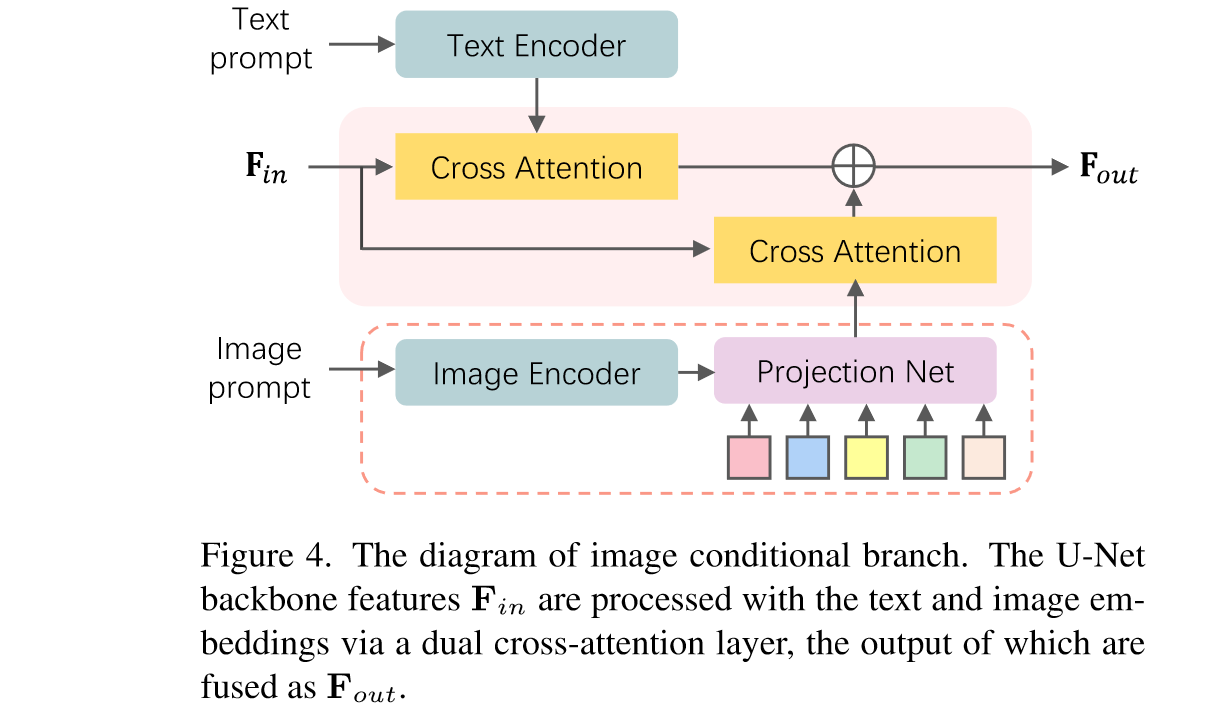
四、总结
其实是一篇技术报告,我估计后续他们可能还会做VideoCrafter2?大概会把VAE加入时序信息,因为感觉它现在生成的video时序一致性还是比较差的。
【2】All in Tokens: Unifying Output Space of Visual Tasks via Soft Token
【URL】http://arxiv.org/abs/2301.02229
【Time】2023-02-14
一、研究领域
Unified Frameworks in Computer Vision
二、研究动机
与语言任务的输出空间通常仅限于一组标记不同,视觉任务的输出空间更加复杂,因此很难为各种视觉任务构建统一的视觉模型。这项工作的目标是将视觉任务的输出空间统一为离散的标记,并构建可以同时处理不同任务的单一模型。
三、方法与技术
包含三个模块:
(1)a tokenizer that encodes the task output to the discrete tokens
(2)a detokenizer that decodes tokens to the task output
(3)a task-solver that predicts tokens from images
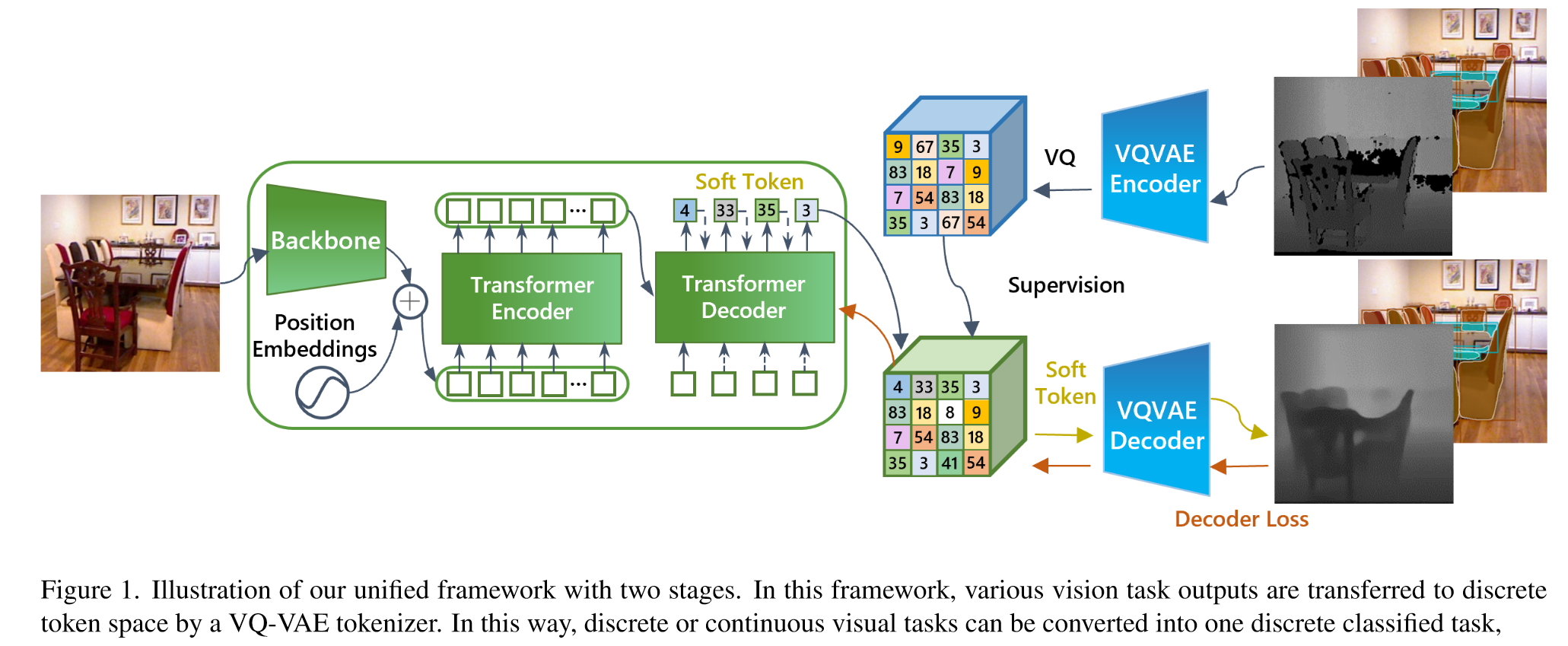
实现方式:
- Tokenizer and Detokenizer:用两个VQVAE实现(分别用两个任务训练:深度估计和实例分割),并且把codebook size从8192减小到128。
- Task-solver:用一个auto-regressive encoder-decoder network实现,其中encoder用Swin Transformer,decoder是自己设计的,含6个block。
- soft token:提出了一种软令牌技术:软令牌不是直接使用单个令牌的嵌入,而是根据预测概率对不同令牌进行加权平均嵌入,用于弥补不同任务训练的VQVAE之间的gap(相对应的hard token是指:在典型的自回归预测过程中,选择具有最大预测概率的标记作为输出,并使用其嵌入作为下一个预测步骤的解码器的输入)。
四、总结
挺有意思的,不知道能不能扩展到更多和更难的任务。
【3】ImageBind: One Embedding Space To Bind Them All
【Time】CVPR 2023
一、研究领域
Joint embedding learning
二、研究动机
学习真正的联合嵌入的一个主要障碍是缺乏大量所有模态同时存在的多模态数据,因此提出了一种方法(不需要所有模式同时出现的数据集)通过使用image将所有模态bind在一起来学习所有模态的单个联合嵌入空间。
三、方法与技术
概念上非常简单:IMAGEBIND 使用模态对(I,M)来学习单个联合嵌入,其中 I 代表图像,M 是另一种模态。因此,即使只使用 (I, M1) 和 (I, M2) 对进行训练,也能够实现 M1 和 M2 的binding。

实现方式:对所有模态的encoder都使用transformer架构,都接一个linear头对齐维度,并且使用了一些预训练模型的encoder来进行初始化。优化方式是 symmetric InfoNCE loss:
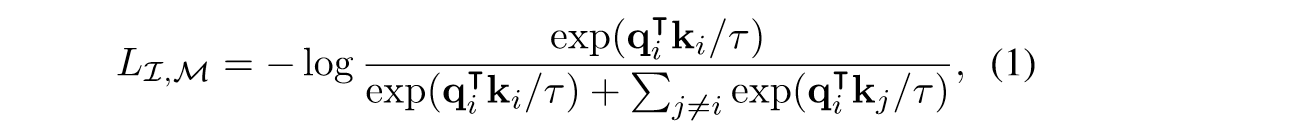
四、总结
是一种很有趣的多模态对齐方法。概念很简洁,实现起来也很灵活。