Daily Trend [10-19]
【1】Language Model Beats Diffusion – Tokenizer is Key to Visual Generation
【URL】https://arxiv.org/abs/2310.05737v1
【Time】2023/10/09
一、研究领域
视频生成,视觉分词器
二、研究动机
提出一种 video tokenizer,旨在使用通用 token vocabulary 为视频和图像生成简洁且 expressive 的 token
三、方法与技术
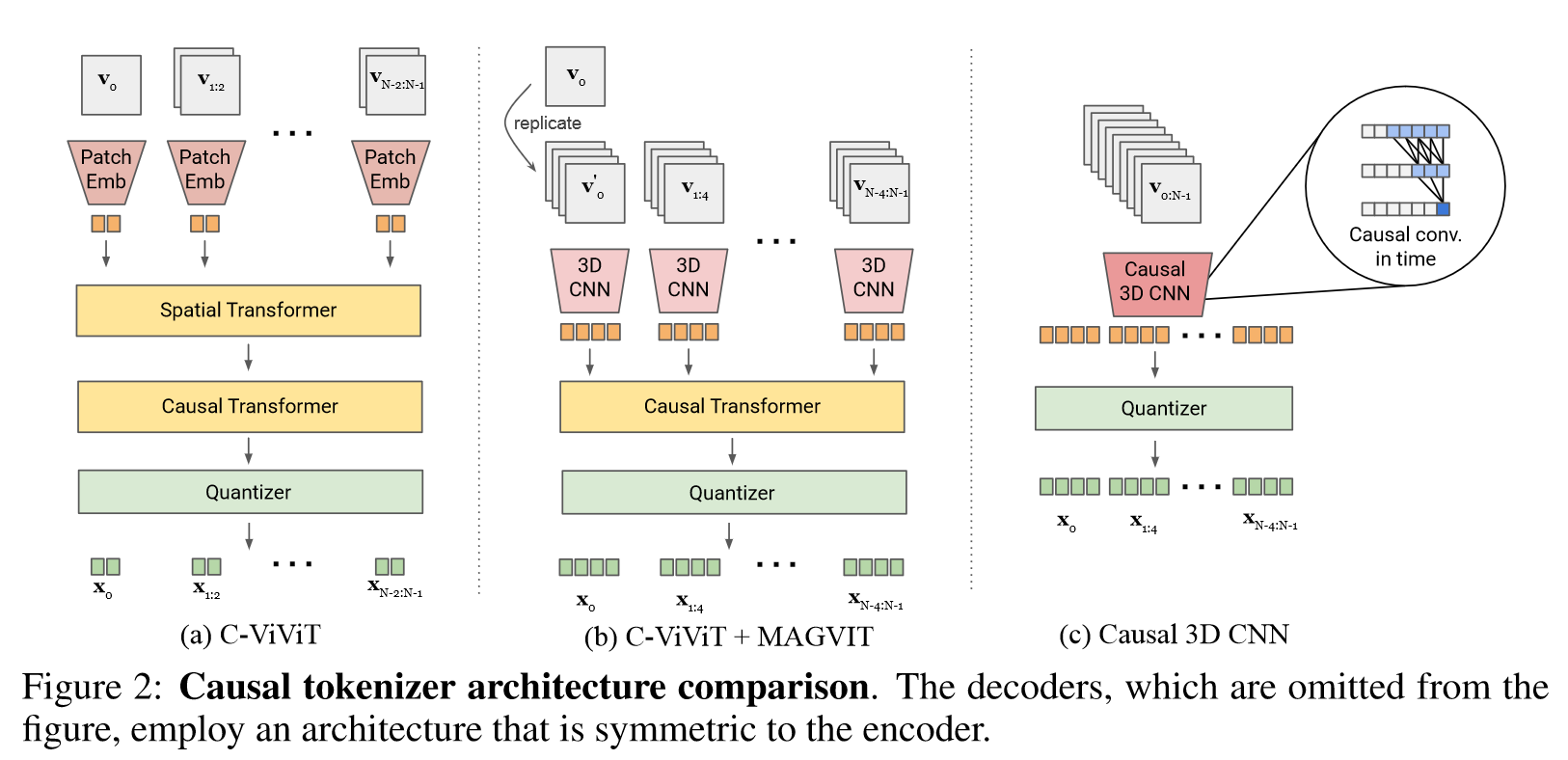
Base Model:MAGVIT
(1)LOOKUP-FREE QUANTIZER(LFQ):通过减少emb维度增加词汇量,使用VQGAN类似的损失
(2)VISUAL TOKENIZER MODEL IMPROVEMENT:结合 C-ViViT 和 3D CNN 架构
四、总结
期待开源
五、推荐相关阅读
MAGVIT: Masked Generative Video Transformer
【2】NUWA-XL: Diffusion over Diffusion for eXtremely Long Video Generation
【URL】https://arxiv.org/abs/2303.12346v1
【Time】2023/03/22
一、研究领域
长视频生成,扩散模型
二、研究动机
希望提出一种简单而有效的视频生成策略,其能够直接在长视频(数千帧)上进行训练,以减少训练与推理之间的差距,并使并行生成所有片段成为可能。
三、方法与技术
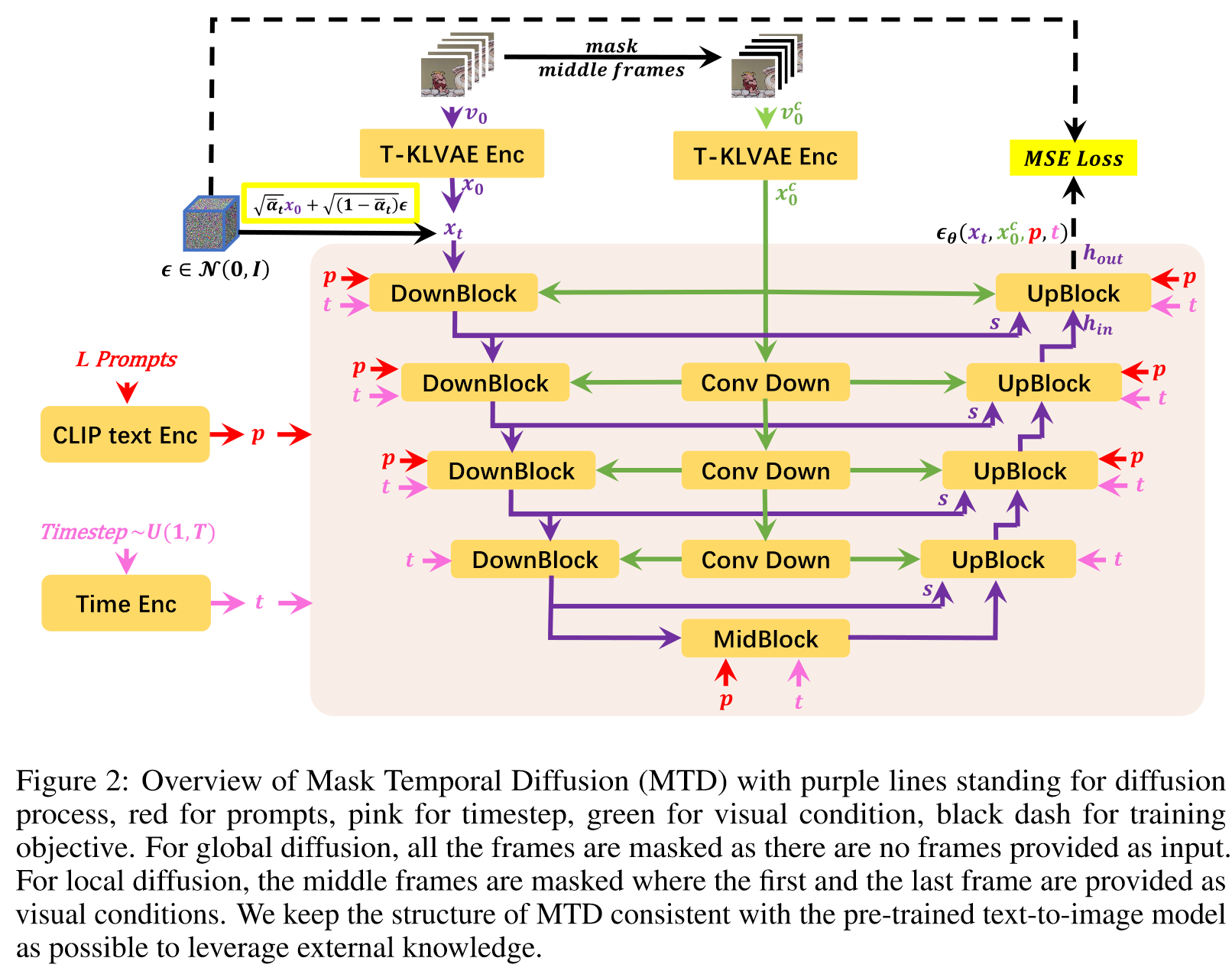
(1)Temporal KLVAE (T-KLVAE):先视为独立图像做空间卷积,再添加时间卷积,训练目标和 image KLVAE 是相同的
(2)Mask Temporal Diffusion (MTD):分为全局扩散和局部扩散,其中全局扩散的条件是L个prompt,局部扩散的条件是L个prompt+第一帧和最后一帧,训练目标是L2扩散目标
(3)Diffusion over Diffusion Architecture:以 coarse-to-fine 的方式生成长视频,其中全局扩散负责生成关键帧,局部扩散负责完成中间帧
四、总结
有人能告诉我全局扩散和局部扩散是共享参数的吗OwO
【3】Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models
【URL】https://arxiv.org/abs/2304.08818v1
【Time】2023/04/18
一、研究领域
视频生成,扩散模型
二、研究动机
希望利用现成的预训练图像 LDM,通过训练时间对齐模型来生成高分辨率视频。
三、方法与技术
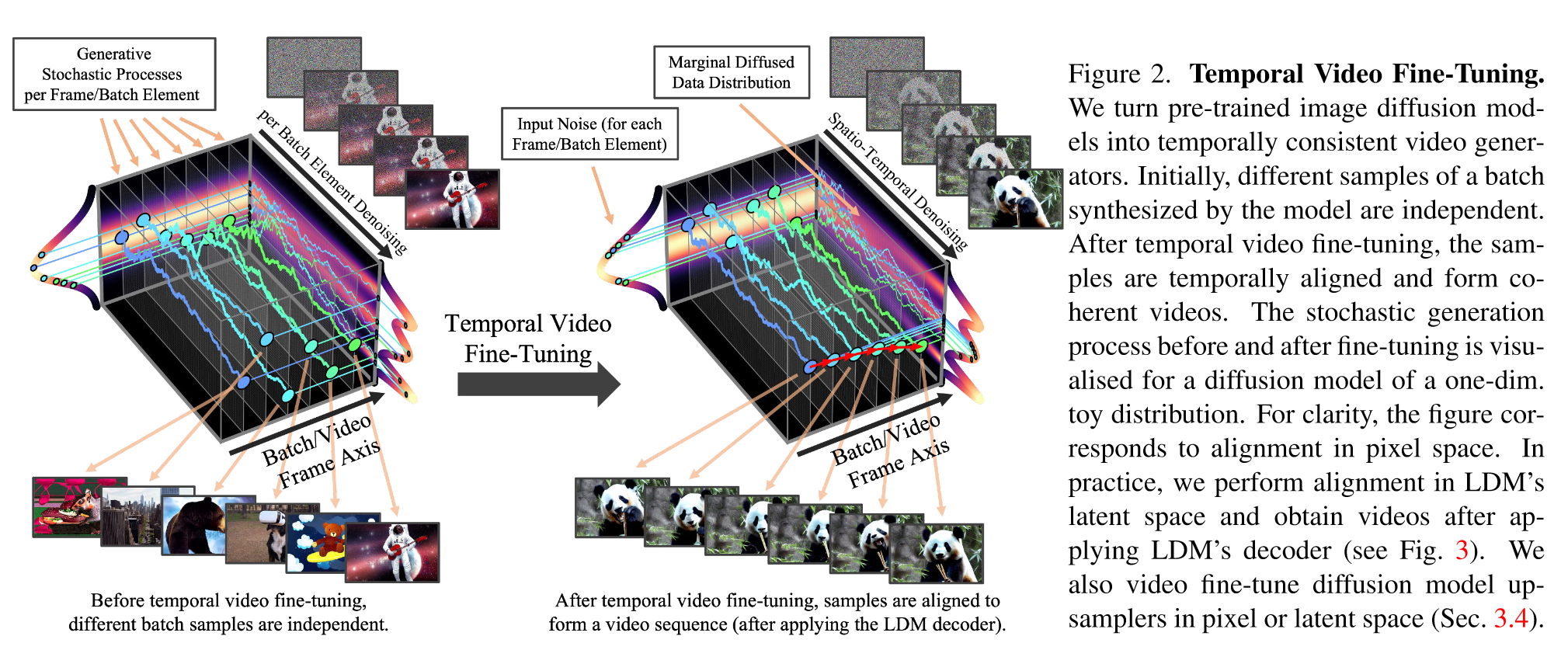
Base Model:预训练的 2D image LDM
(1)Turning Latent Image into Video Generators:在spatial layer后面插入时间层,保持主干参数不变,仅训练 temporal layer 的参数,在视频数据上微调。Encoder不做改变。
(2)Prediction Models for Long-Term Generation:引入时间二进制掩码,将模型训练为condition在上下文帧中的,以实现长视频生成,训练方式是CFG
(3)Temporal Interpolation for High Frame Rates:引入另一个模块对关键帧插值以提高帧率
(4)Temporal Fine-tuning of SR Models:级联架构训练超分模块以提高视频分辨率
四、总结
Pipeline很完善,很直观,模块很多,比较复杂
【4】Visual Instruction Tuning
【URL】http://arxiv.org/abs/2304.08485
【Time】2023-04-17
一、研究领域
MLLM,指令微调
二、研究动机
(多模态)视觉指令微调
三、方法与技术
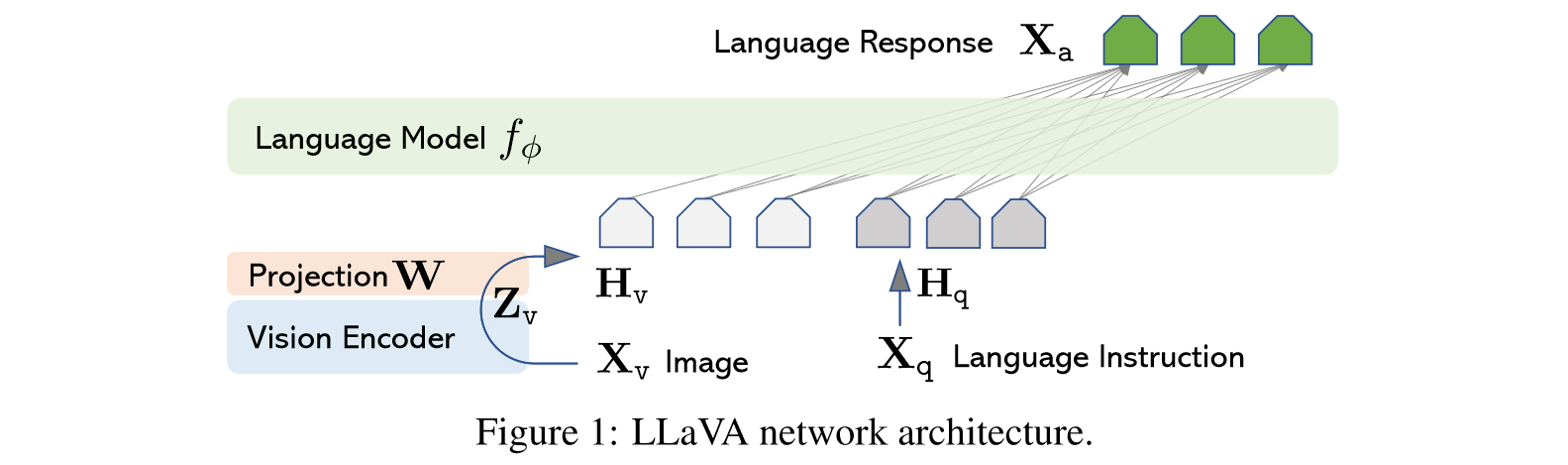
Base Model:LLaMA
用一个简单的投影层将CLIP图像特征连接到词嵌入空间一起训练,训练过程分为两阶段
(1)Pre-training for Feature Alignment:冻结LLM和visual encoder训练投影层,这个阶段可以理解为为冻结的LLM训练一个兼容的 visual tokenizer
(2)Fine-tuning End-to-End:只保持visual encoder权重冻结,并继续更新LLaVA中投影层和LLM的预训练权重
四、总结
极简的 pipeline 极高的潜力
五、推荐相关阅读
Improved Baselines with Visual Instruction Tuning
【5】Improved Baselines with Visual Instruction Tuning
【URL】http://arxiv.org/abs/2310.03744
【Time】2023-10-05
一、研究领域
MLLM
二、研究动机
LLaVA升级(12边形战士)
三、方法与技术
(1)数据和数据格式修改
(2)线性投影层改为双层MLP
(3)添加学术导向的任务
(4)提高图像分辨率
以下是和SoTA的对比:
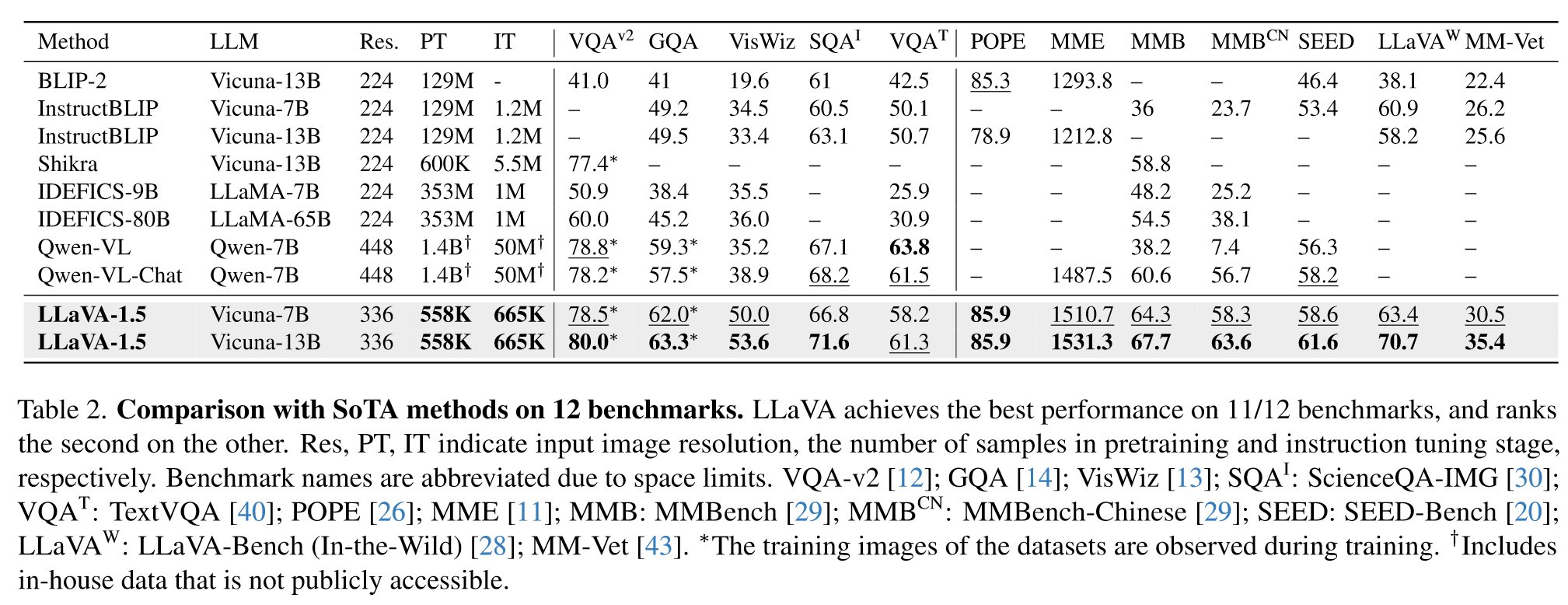
四、总结
LLaVA v1.5 已经开源咧
五、推荐相关阅读
Visual Instruction Tuning