Daily Trend [10-16]
1【Title】AgentTuning: Enabling Generalized Agent Abilities for LLMs

【URL】https://openreview.net/forum?id=OqlmgmS4Wr
【Time】2023/10/13
一、研究领域
LLM、Agent
二、研究动机
提高LLM的代理能力(可泛化)而不损害LLM本身的语言能力。
三、方法与技术
构建指令数据集和混合微调。基座模型是Llama 2。
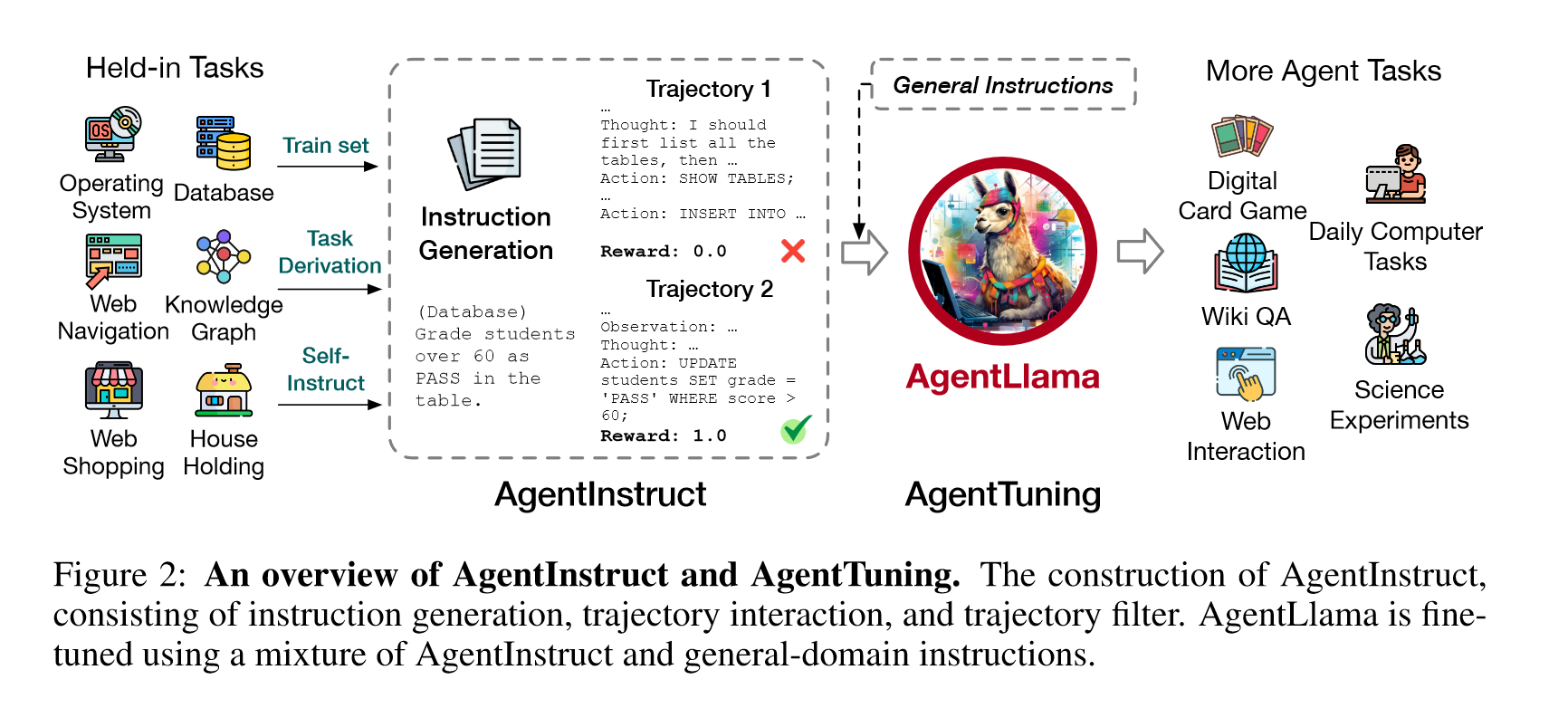
四、总结
代理能力(70B)齐平GPT-3.5
2 【Title】Flexible Diffusion Modeling of Long Videos

【URL】http://arxiv.org/abs/2205.11495
【Time】2022-12-15
一、研究领域
长视频生成、扩散模型
二、研究动机
在各种真实环境中生成长视频
三、方法与技术
以多帧集合为条件的多帧集合生成
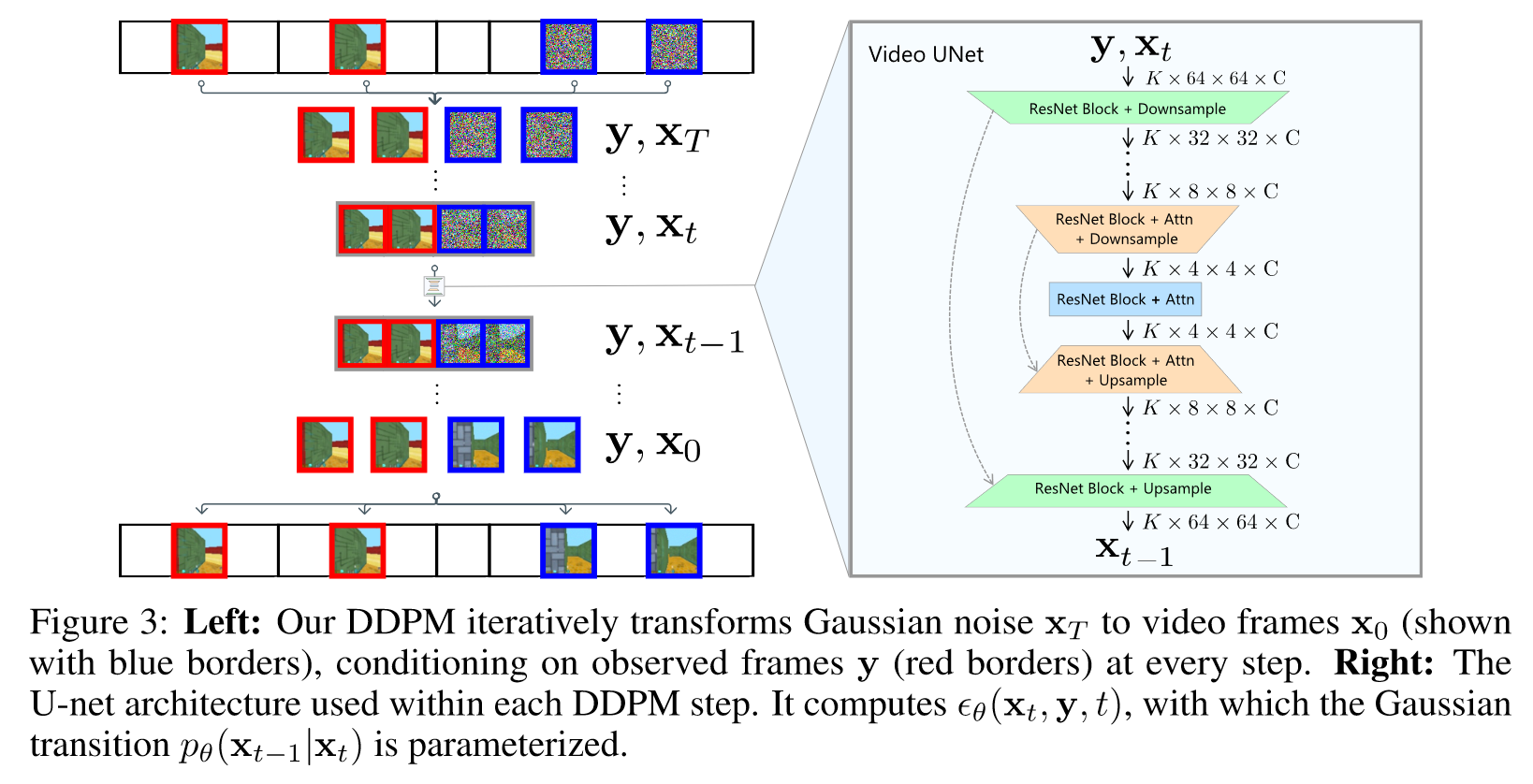
四、总结
可以生成25分钟不降低质量的长视频(在数据集CARLA Town01 and MineRL上)
3 【Title】Learning to Play Atari in a World of Tokens

【URL】https://openreview.net/forum?id=rPpRyGVVnt
【Time】2023/10/13
一、研究领域
世界模型,策略学习
二、研究动机
一种利用 Transformer 学习world model和policy的新颖方法
三、方法与技术
(1)用VQ-VAE做tokenizing
(2)用GPT架构对环境动态做自回归建模
(3)用ViT对policy做线索建模
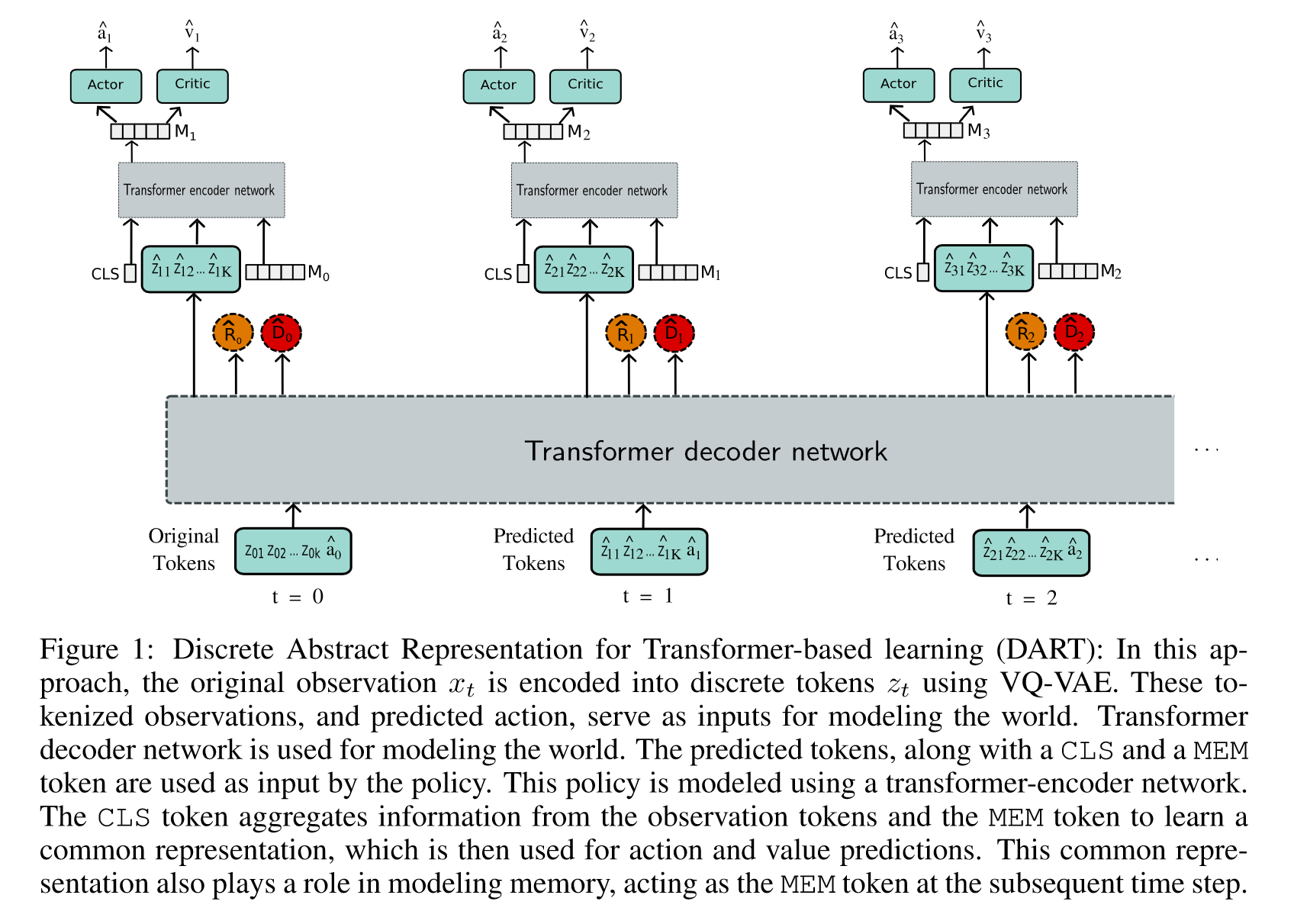
四、总结
DART 在 Atari 26 场游戏中的 9 场击败了人类。
五、推荐相关阅读
GAIA-1: A Generative World Model for Autonomous Driving
4 【Title】GAIA-1: A Generative World Model for Autonomous Driving

【URL】http://arxiv.org/abs/2309.17080
【Time】2023-09-29
一、研究领域
世界模型,自动驾驶,视频生成
二、研究动机
结合world model的能力,利用视频、文本和动作输入来生成真实的驾驶场景,同时提供对自动驾驶车辆行为和场景特征的细粒度控制。
三、方法与技术
(1)使用DINO特征预训练一个image tokenizer
(2)使用自回归网络(world model)建模环境动态,同时训练无条件/action条件/text条件生成
(3)使用world model生成的token作为条件,四任务上联合训练video diffusion model作为video decoder
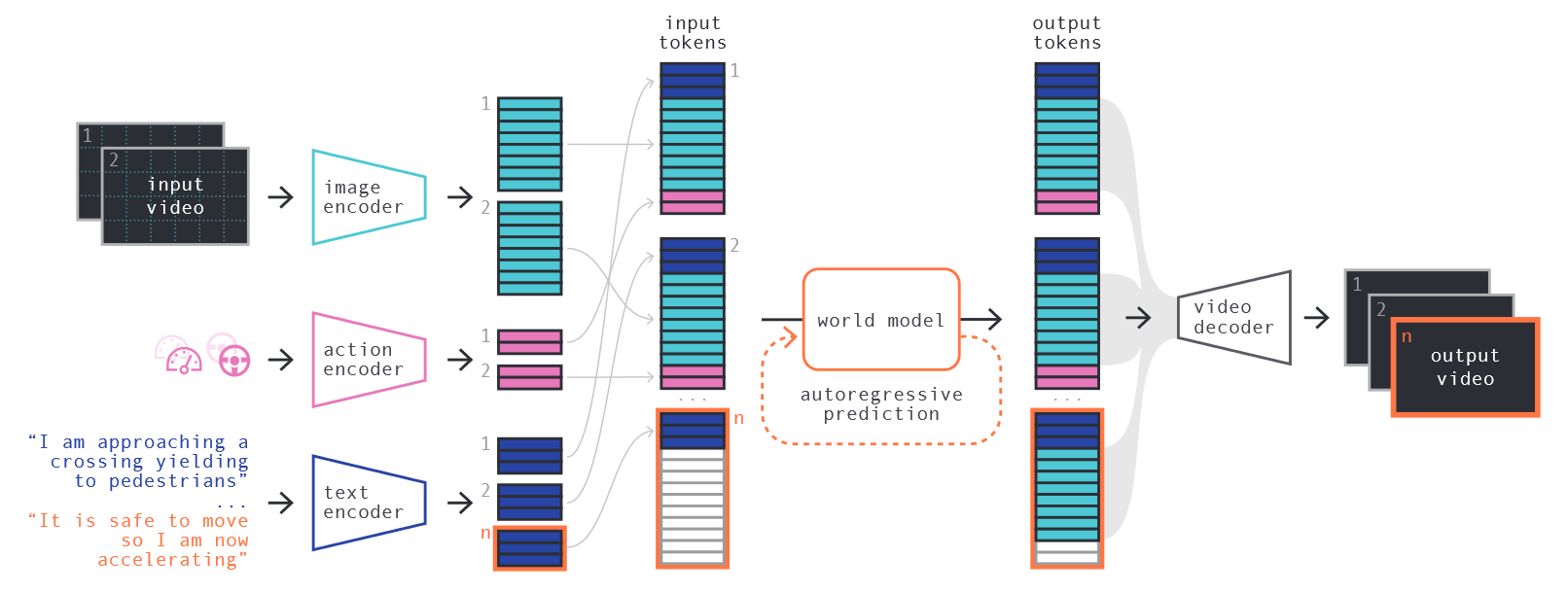
四、总结
GAIA-1 的重要性超出了其生成能力。世界模型代表了实现能够理解、预测和适应现实世界复杂性的自主系统的关键一步。