DreamSparse - 每日一读[7.19]

论文链接:
http://arxiv.org/abs/2306.03414
发布时间:2023.6.16
一、研究方向:
novel view synthesis, 单物体/场景级别的少视角, lift 2D to 3D
二、研究动机:
task:利用预训练的2D diffusion帮助少视角3D生成任务
novelty:不需要逐对象训练
insight:
- 需要为2D扩散模型引入3D先验,即多视角的聚合特征
- 需要保证生成的新视角与ref gt的identity一致性
三步走策略:
- 感知:用一种3D Geometry Module来聚合3D特征
- guidance:提出了一种spatial guidance来使用聚合特征引导扩散模型,保证几何一致性
- identity:提出了一种noise perturbation method,保证identity一致性
三、方法与技术:
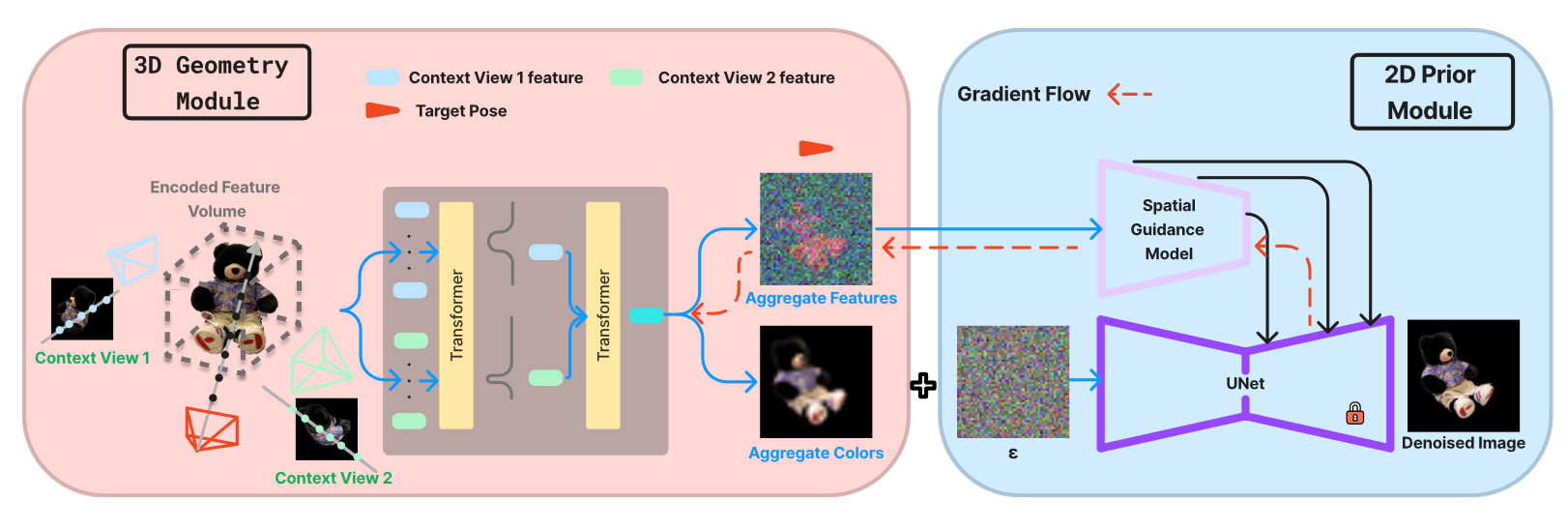
(input:一组上下文图像,output:新视角合成)
- 训练3D Geometry Module
单张图像逐点密度加权:ResNet主干提取语义特征&reshape成4维体积表示,双线性采样对齐空间维度,三线性插值拼接特征向量,线性投影层加权
上下文图像特征聚合:对每条查询射线target,计算每个相应上下文图像的相应射线特征,然后聚合:
颜色聚合:
 spatial feature的可视化
spatial feature的可视化
2. 为spatial guidance训练controlnet:
 T是引导模块
T是引导模块
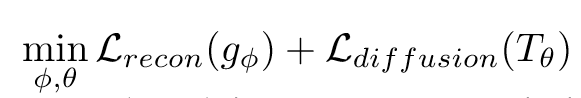 在训练时,使用真实图像作为 x0 来优化 L_diffusion,在推理时,使用从 gφ,color 渲染的图像来初始化 x0。
在训练时,使用真实图像作为 x0 来优化 L_diffusion,在推理时,使用从 gφ,color 渲染的图像来初始化 x0。
3. noise perturbation method:加一定steps的噪声(其实说白了就是控制去噪步数)
pipeline:
四、实验结果:
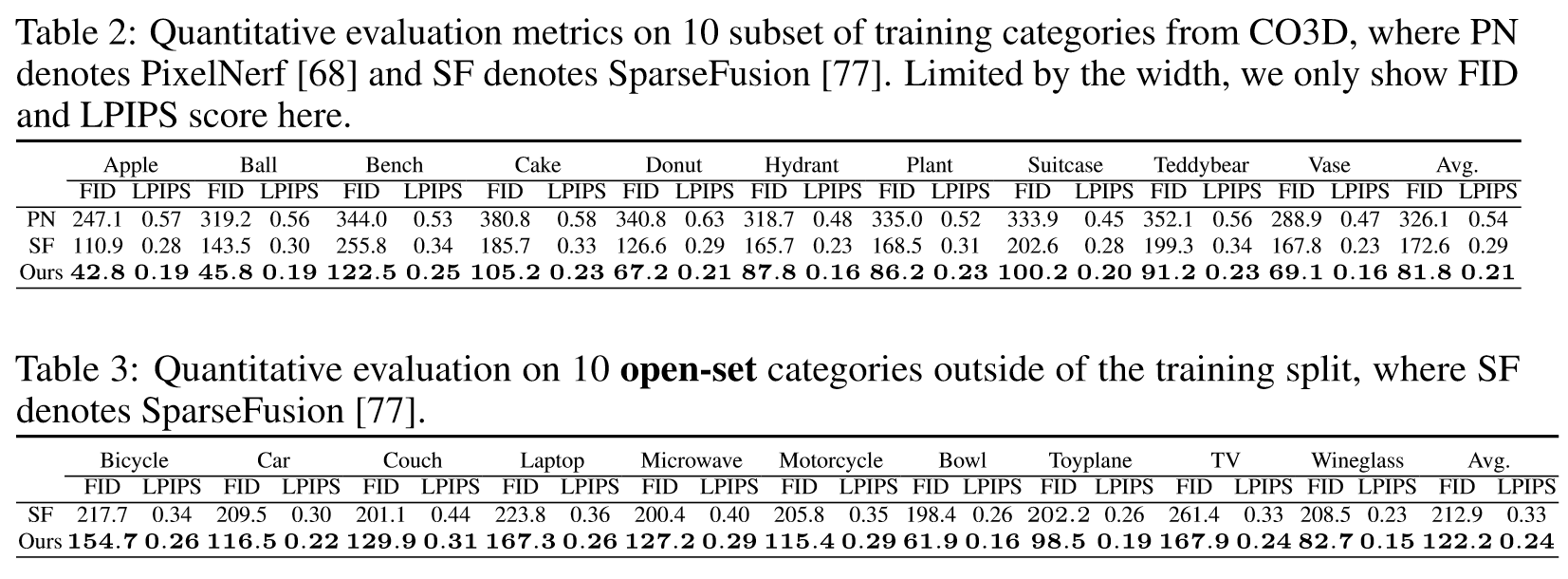
- 和baseline比较

2. LPIPS Score 和FID:
3. 新视角合成(物体级别和场景级别)

4. 结合文本引导

5. Ablation
- spatial guidance 的 CFG Scale:

- noise perturbation 的 steps:

五、主要贡献:
- 少视角重建
- 可泛化
评价:
- noise perturbation保证一致性看起来不太科学,和identity consistency其实关系很弱,感觉主要还是因为和spatial guidance的配合
- limitation:很难生成复杂场景
- 但是gemometry感知和引导的方法值得学习
推荐相关阅读:
- Sparsefusion: Distilling view-conditioned diffusion for 3d reconstruction
- Generative novel view synthesis with 3d-aware diffusion models
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.