Collaborative Score Distillation - 每日一读[7.14]

论文链接:
http://arxiv.org/abs/2307.04787
发布时间:2023.7.4
一、研究方向:
跨模态的视觉生成任务,包括全景图像、视频和3D场景编辑,对标SDS Loss(可以结合我们之前讲解过的DDS和VSD进行比较)。
二、研究动机:
task:如何将预训练的文本到图像扩散模型的知识应用于二维图像之外的更复杂的高维视觉生成任务(全景图像、视频、3D),而无需使用特定于模态的训练数据修改扩散模型(Zero-shot)
insight:许多复杂的视觉数据,例如视频和 3D 场景,都被表示为一组受特定模态一致性约束的图像(例如时间一致性和视角一致性),但是普通的扩散模型生成结果是不具有这种一致性的
related work:SDS Loss,其实是一种3D object先验,并且尚未被用于其他模态
获得神秘启发:
- 使用 Stein 变分梯度下降 (SVGD) 建立 SDS 的泛化,其中多个样本共享从扩散模型中提取的知识,以实现样本间的一致性
- 结合Instruct-Pix2Pix来进行一致视觉编辑(指令引导的扩散模型,任务显而易见地包括三元组:src image,instruction y,edited image)
三、方法与技术:
- 回顾
- CFG Guidance(前面的文章有讲过):
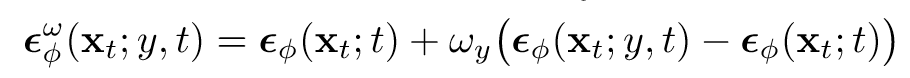
(Kim 等, 2023, p. 3)其中w是guidance scale
条件模型和无条件模型的混合实现text引导。
- Instruct-Pix2Pix(之后的文章会讲):
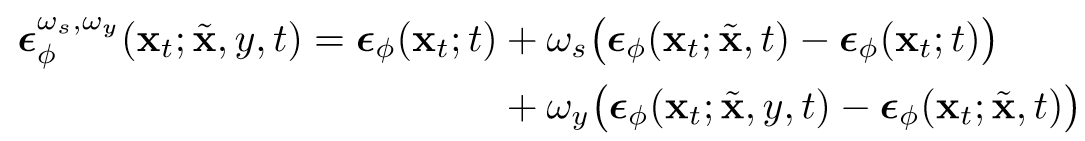
(Kim 等, 2023, p. 3)其中wy是cfg guidance scale,ws控制fidelity
cfg类似思路,实现src img+instruction text的引导
- SDS Loss(典)
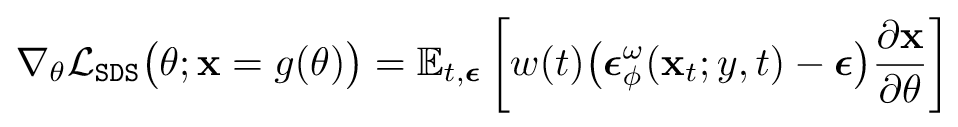
(Kim 等, 2023, p. 4)
蒸馏2D generations到3D representations
- SVGD
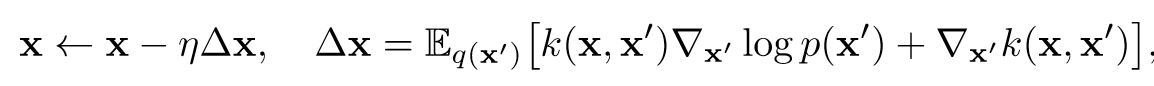
(Kim 等, 2023, p. 5)一种梯度下降方法,这里具体采用RBF核
2. CSD(多个样本的一致合成和编辑)
- CSD Loss(多样本一致的合成):
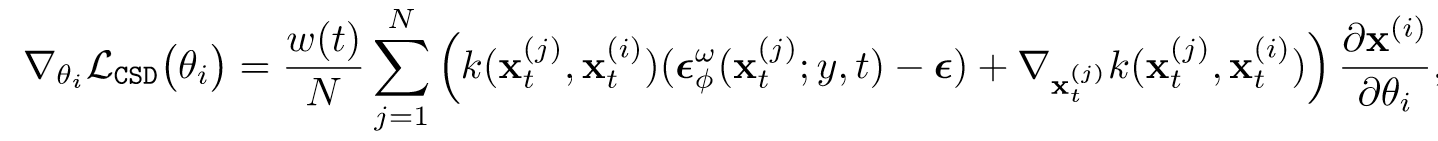
(Kim 等, 2023, p. 5)依然和VSD类似,用一组参数θ来建模先验分布,然后按权重混合N个样本的分数,特别地,其中的kernel梯度(黄色项)充当排斥里以防止模式崩溃。噪声项左乘kernel(蓝色项)的作用是保证θi 上的每个参数更新都会受到其他参数的影响。
- CSD-Edit Loss(多样本一致的编辑)
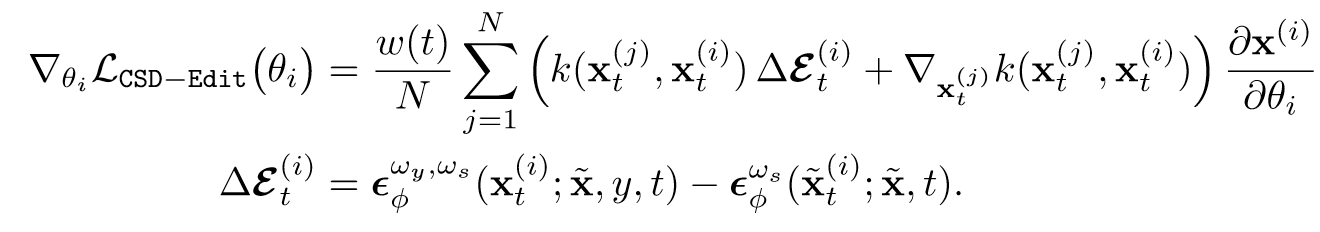
(Kim 等, 2023, p. 6)把噪声估计项的基线改为了instruct-pix2pix中的噪声估计,以引入zero-shot的编辑能力。
3. Pipeline
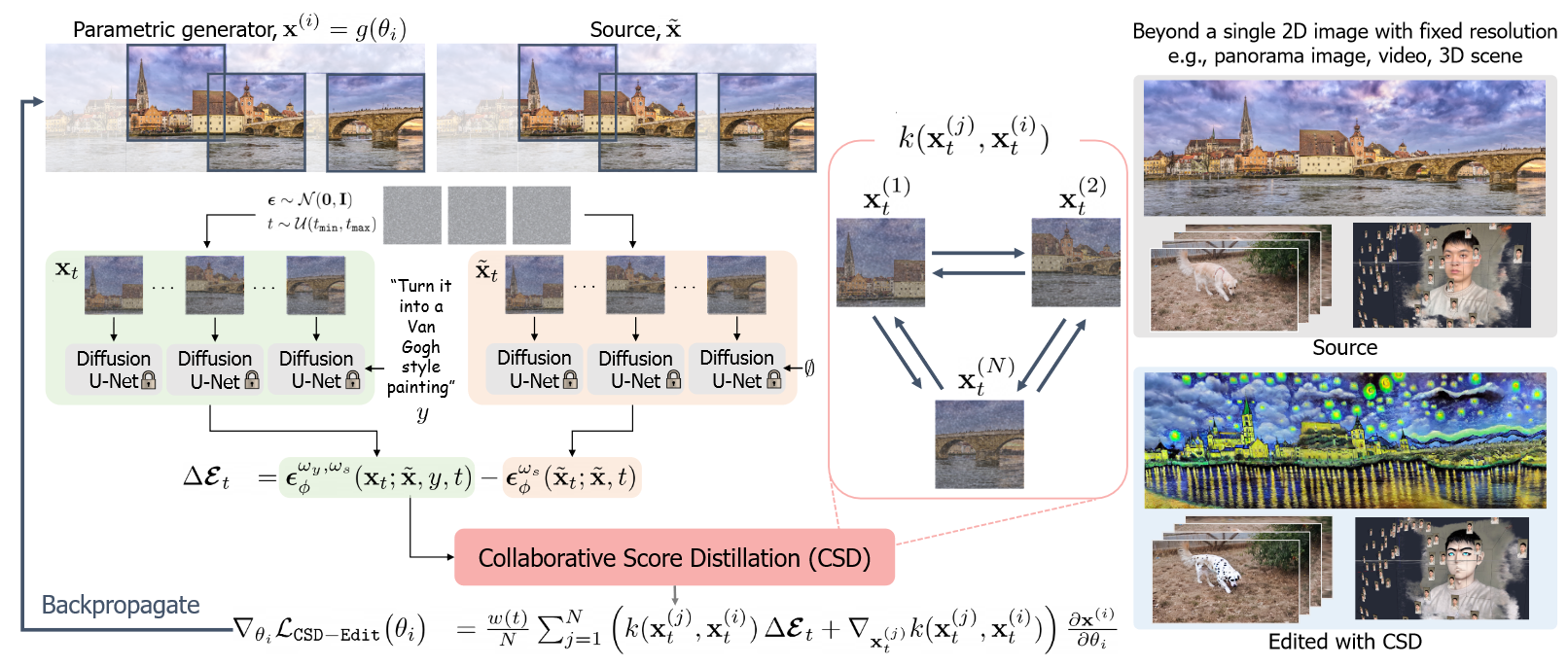
(Kim 等, 2023, p. 2)
四、实验结果:
- 全景图像编辑:空间一致(多块优化)

(Kim 等, 2023, p. 3)
2. 视频编辑:时间一致性(多帧优化)

(Kim 等, 2023, p. 4)
3. 3D场景编辑:视图一致性

(Kim 等, 2023, p. 5)
4. text-to-3D Generation

(Kim 等, 2023, p. 8)
5. Ablations: 有无SVGD

(Kim 等, 2023, p. 9)
6. CLIP Scores 和 LPIPS

(Kim 等, 2023, p. 7)
五、主要贡献:
提出了协作分数蒸馏(CSD)以实现一致的视觉合成和操作。
提出了 CSD-Edit,它通过从指令引导的扩散模型中提取最少但足够的信息来对图像进行一致的编辑。
评价:
- 粒子的思路和VSD非常像,但是实现方式上完全不同(CSD用kernel,VSD用lora)
- novelty在于kernel和SVGD的引入可以同步优化多个样本
- novelty也适用于多个模态的生成和编辑,不仅仅是3D
- eidt的思路类似于DDS
推荐相关阅读:
- ProlificDreamer: High-Fidelity and Diverse Text-to-3D Generation with Variational Score Distillation
- DreamFusion: Text-to-3D using 2D Diffusion
- Delta Denoising Score
- InstructPix2Pix: Learning to Follow Image Editing Instructions