Delta Denoising Score - 每日一读[7.12]

论文链接:http://arxiv.org/abs/2304.07090
发布时间:2023-04-14
一、研究方向:
T2I图像编辑(zero-shot,text-only)
二、研究动机:
对标DreamFusion的SDS Loss,提出了一种新的优化目标称为DDS Loss用于2D图像编辑。可以认为DDS Loss是校正后的SDS Loss。(记住它们,之后的文章还会讲VSD Loss和CSD Loss)。

先怼SDS作为2D先验的缺点:
- 多样性差,模式单一
- 编辑结果模糊(因为是文本图像一对一优化)
然后得到神秘启发:
- 认为SDS包含一些不必要的梯度导致了上述模式崩溃
- 通过reference的图像-文本描述对,估计SDS引入的不良噪声梯度方向。
- 所以,指导target图像的编辑的时候用SDS Loss减掉它就好了
三、方法与技术:
- 分解SDS Loss
先回顾一下大家都很熟悉的SDS Loss(它本来是用来做3D生成任务的,但是其实也可以扩展到图像编辑任务):
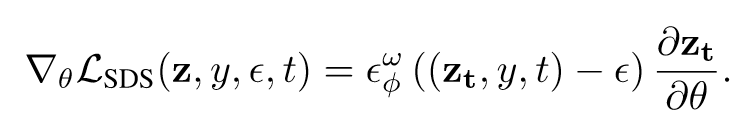
作者认为其中包含了导致崩坏的梯度项,于是对其分解(为text项和bias项):
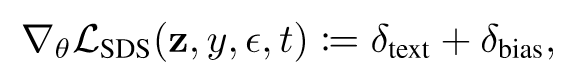
2. 通过去除bias项构建DDS Loss:
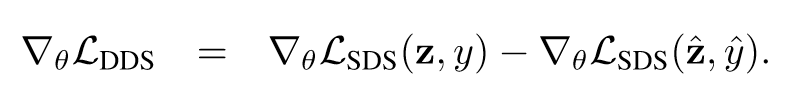
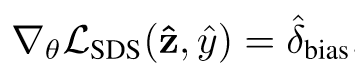
其insight是只想用新的文本描述来更改图像的一部分,所以认为reference图像-文本对的SDS梯度等价于bias项,因此减去它得到的DDS Loss就是text项。
3. 正则化项
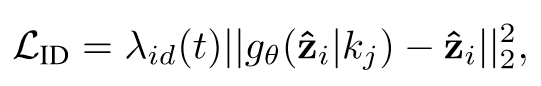
目标是提高fidelity。
4. warm up
调整CFG Guidance(即参数w)
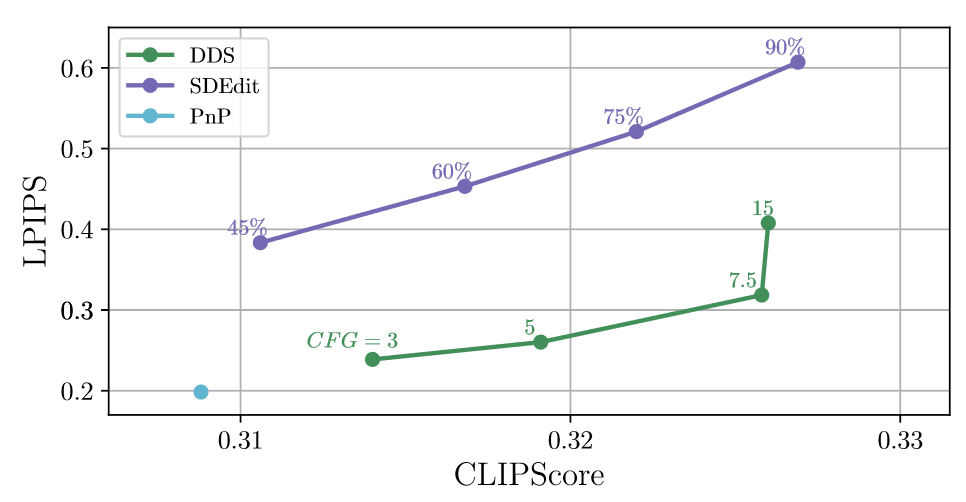
四、实验结果:
- CLIP Score和LPIPS
2. Zero shot image editing qualitative comparison

3. Image-to-Image translation comparison

5. Ablation:主要是比较不同CFG guidance
评价:
- 数学原理并不是很靠谱
- 效果还不错
- 依然受于CFG分数困扰
- 有点像negative prompt的思路
推荐相关阅读
- Collaborative Score Distillation for Consistent Visual Synthesis
- ProlificDreamer: High-Fidelity and Diverse Text-to-3D Generation with Variational Score Distillation
- DreamFusion: Text-to-3D using 2D Diffusion
http://y-ichen.github.io/2023/07/12/Delta-Denoising-Score-%E6%AF%8F%E6%97%A5%E4%B8%80%E8%AF%BB-7-12/
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.