pixelNeRF - 每日一读[8.7]

论文链接:http://arxiv.org/abs/2012.02190
发布时间:2021-05-30
一、研究方向:
少视角合成,单视图重建
二、研究动机:
issues:
- NeRF需要许多输入视图和逐场景大量优化时间
- 传统少视角合成方法的相机姿态受限
- 传统方法需要3D监督或者mask
- 大多数现有方法在canonical space中运行
motivation:
- 少视角合成,跨场景泛化
- PixelNeRF是完全前馈的,只需要相对的相机姿态
- 只需要image监督
- PixelNeRF 在view space中运行,可以更好地重建未见的对象类别,并且不鼓励记忆训练集
三、方法与技术:
- 单视角合成:
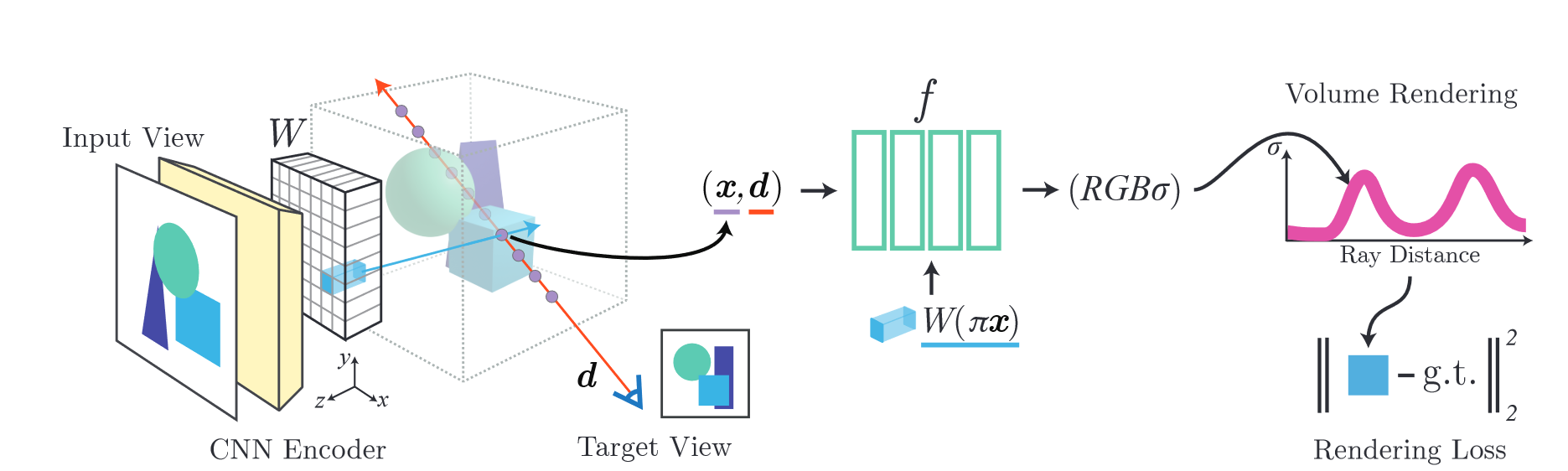
图片先过卷积得到特征W,然后对于沿着具有视角方向d的目标摄像机射线的查询点x,通过投影和插值从特征体W中提取相应的图像特征。然后将该特征与空间坐标一起传递到 NeRF 网络 f 中。输出的 RGB 和密度值经过体积渲染并与目标像素值进行比较。坐标 x 和 d 位于输入视图的相机坐标系中。
2. 少视角合成(数量可变):
对于每个已知视角同上思路计算中间值Vi:
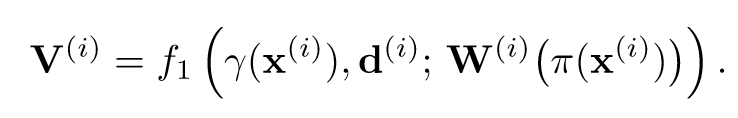
聚合每个Vi预测最终的RGB和密度值:
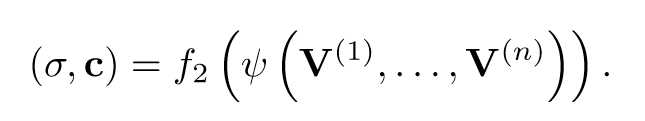
四、实验结果:
单类别训练的:
单视角重建

2-视角重建
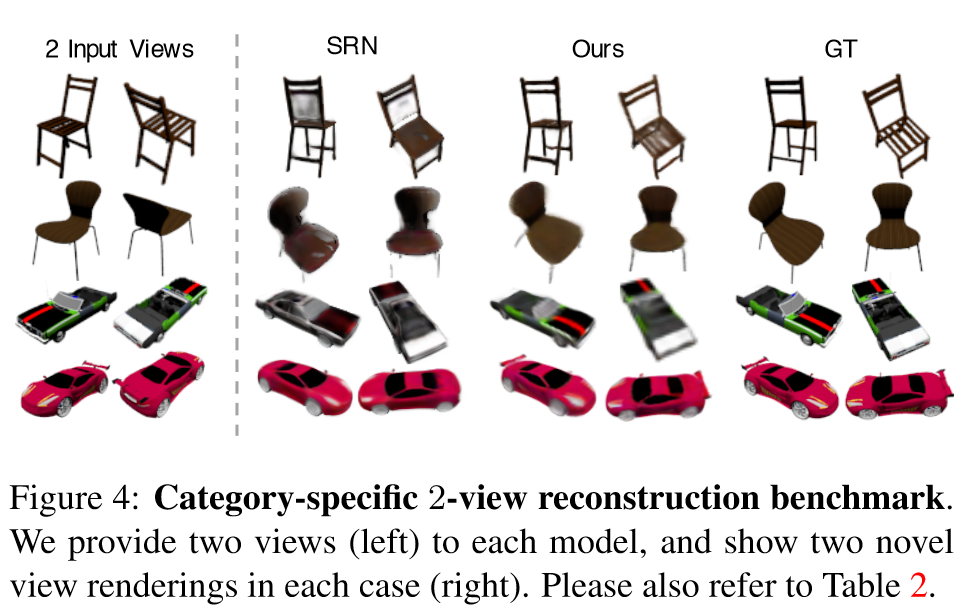
类别无关训练的:
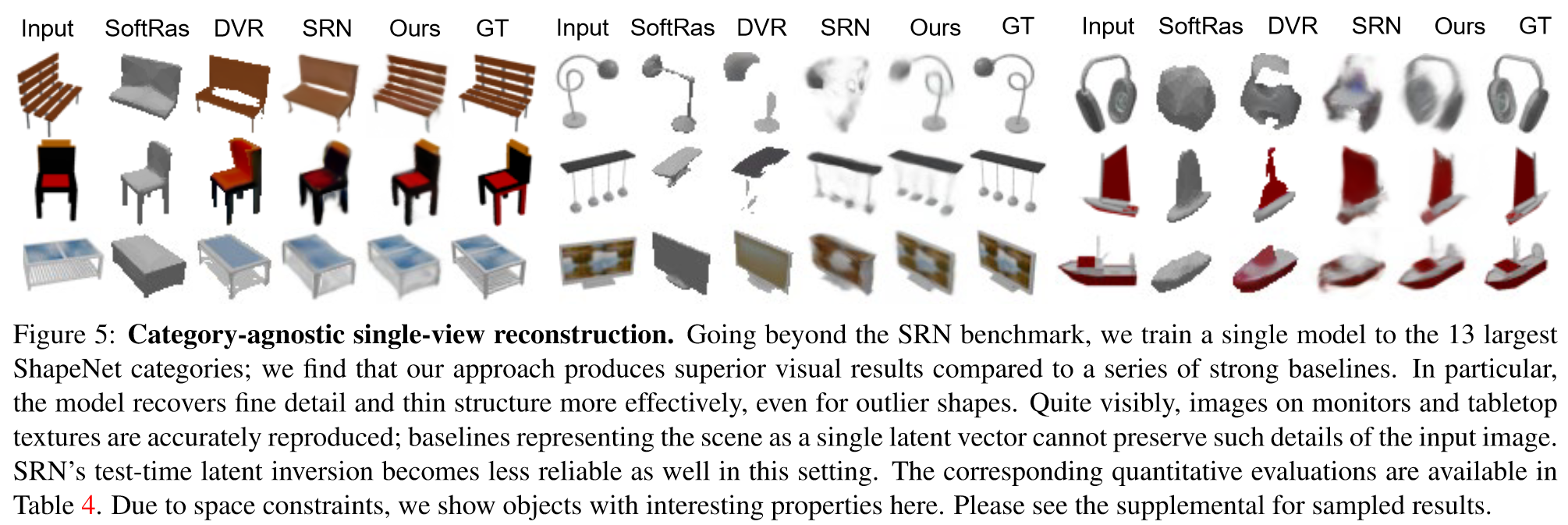
泛化到未见类别:

360°重建:

真实数据集上:

评价:
- 从论文呈现的结果来看真实数据集上的表现并不好
- CNN限制了合成精度
推荐相关阅读:
- pixelNeRF: Neural Radiance Fields from One or Few Images
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.