Prompt-to-Prompt - 每日一读[7.18]

论文链接:
http://arxiv.org/abs/2208.01626
发布时间:2022.8.2
一、研究方向:
text-driven image editing(任务包括局部编辑,全局编辑,单词语义效果编辑,都是text-only的)
二、研究动机:
- task: 设计一种直观的prompt-to-prompt编辑框架,其中编辑仅由文本控制

2. insight: 在扩散过程中注入cross attention map, 通过修改交叉注意层中发生的像素到文本的交互, 实现图像编辑
三、方法与技术:
- 根据图像和文本计算attention map:
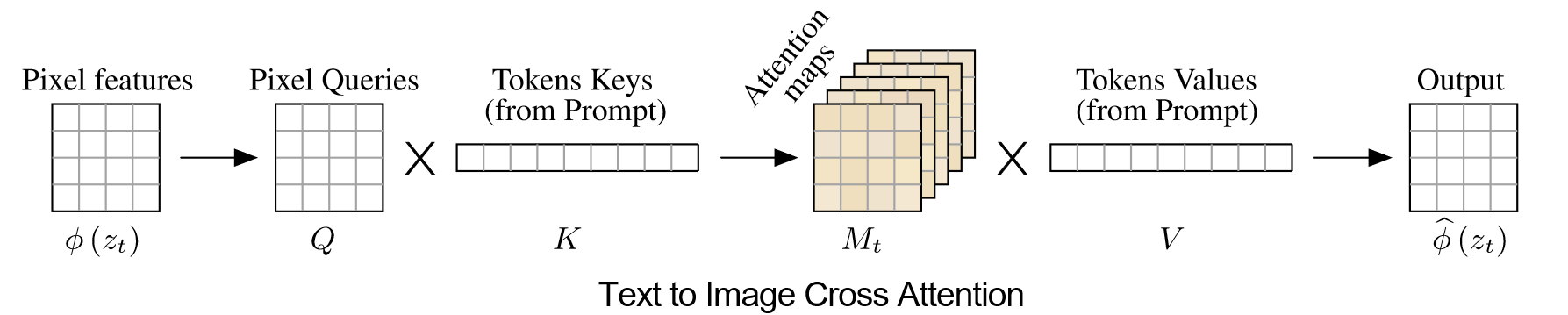
 Q是图像feature,KV是文本embeddings,M是输出的attantion map
Q是图像feature,KV是文本embeddings,M是输出的attantion map
2. 通过编辑扩散过程的cross attention map来实现图像编辑
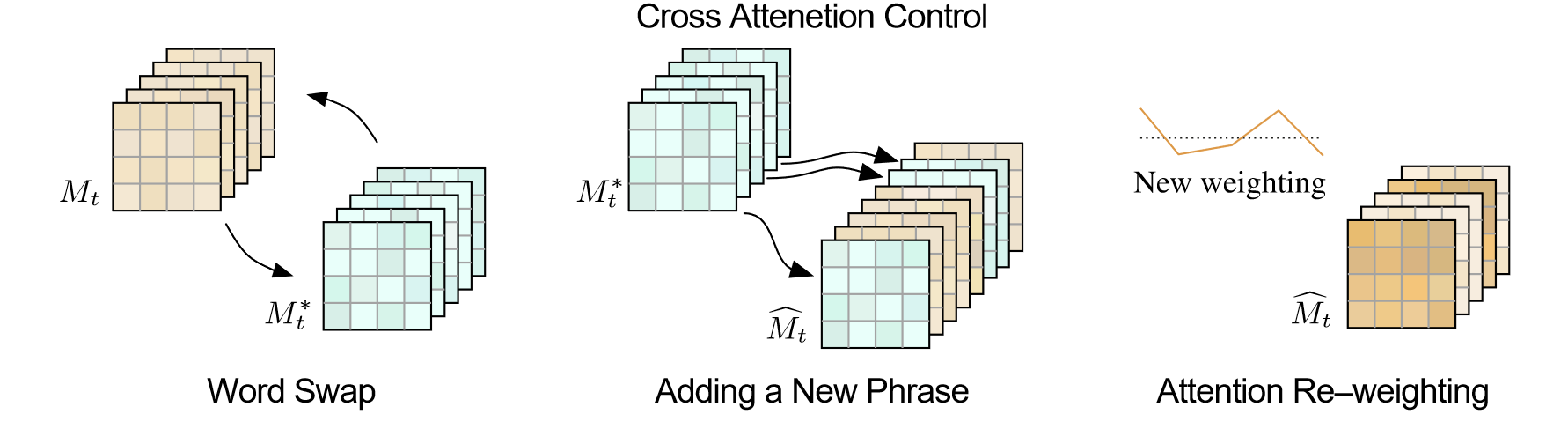
这里区分三种类型的编辑任务:
- Word Swap(P =“a big red bicycle” -> P∗ =“a big red car”):直接把attention map替换成编辑目标的.
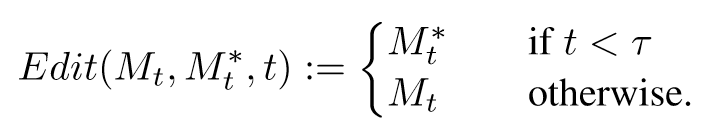
- Adding a New Phrase (P =“a castle next to a river” to P∗ =“children drawing of a castle next to a river”): 创建一个索引,原有的token使用原有的attention map,新增的token索引到新的attention map
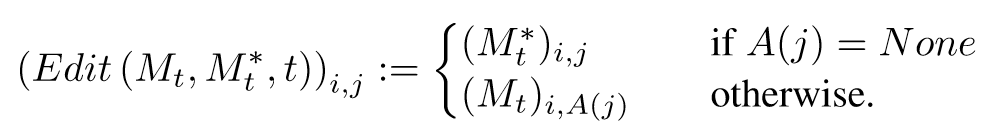
- Attention Re-weighting (P = “a fluffy red ball”, and assume we want to make the ball more or less fluffy): 按-2~2的权重缩放
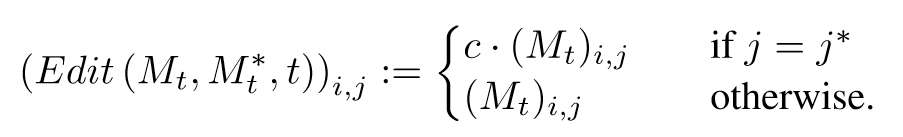
四、实验结果:
- Text-Only Localized Editing

2. Global editing.

3. Fader Control using Attention Re-weighting.

五、主要贡献:
- 通过cross attn控制扩散过程
- 不需要inversion
评价:
- 是非常科学的控制方法
- limitation是没有空间感知和移动能力
- 计算策略不够灵活
推荐相关阅读:
- InstructPix2Pix: Learning to Follow Image Editing Instructions
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.