ProlificDreamer - 每日一读[7.13]

论文链接:
http://arxiv.org/abs/2305.16213
发布时间:2023.5.25
一、研究方向:
提出新的text-to-3D蒸馏方案VSD Loss,对标DreamFusion的SDS Loss。实验结果相当炸裂,是text-to-3D生成模型领域的突破性工作。
二、研究动机:
- 经典的lift 2D to 3D动机:
利用预训练的扩散模型实现text-to-3D的生成任务。
2. 经典,怼SDS存在的问题:
过饱和、过平滑、低多样性(生成结果的模式单一)
3. 获得神秘启发:
- 不能像SDS那样单点优化
- 因为多个3D场景应当和一个提示对齐(多对一,而非一对一),所以把将3D场景视为满足一定先验分布的随机变量,而不是变量
- 维护一组3D参数作为粒子来表示这个基于给定文本提示的3D分布(后面说到用lora实现)
- 使用低至7.5的CFG分数(这样就不容易模式崩溃,更符合在分布中“采样”的思路,区别于SDS的100)
三、方法与技术:
- 回顾SDS Loss
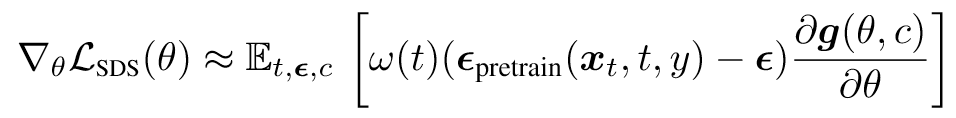
2. 对服从文本提示y的3D分布建模,并且和扩散模型对齐:
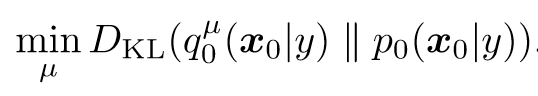
3. 用一组θ表示粒子,推导出优化目标:
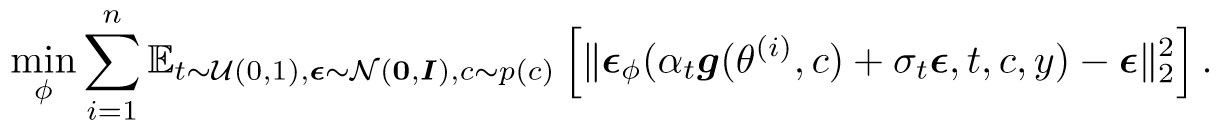
注意它的实现:
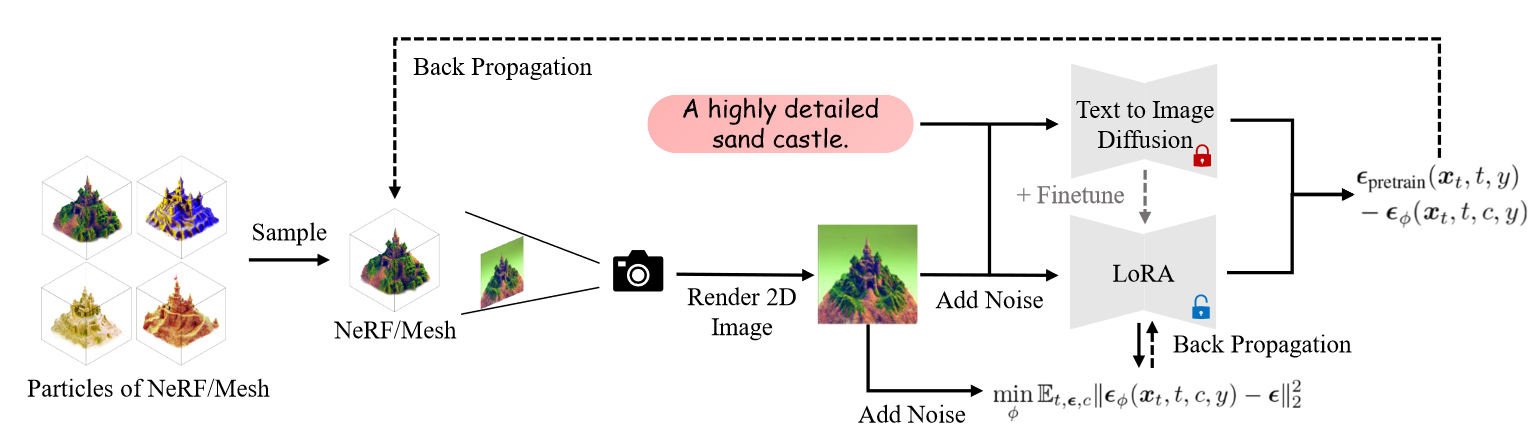
在实践中,我们通过预训练模型 εpretrain(xt, t, y) 的小型 U-Net [38] 或 LoRA(低秩自适应 [18, 39])对 εφ 进行参数化,并将额外的相机参数 c 作为条件嵌入添加到网络。
“In practice, we parameterize εφ by either a small U-Net [38] or a LoRA (Low-rank adaptation [18, 39]) of the pretrained model εpretrain(xt, t, y), and add additional camera parameter c to the condition embeddings in the network.” (Wang 等, 2023, p. 6)
4. 最终推出VSD Loss(显而易见和SDS的区别在于后一项)
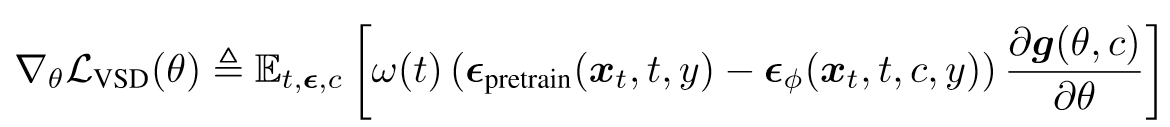
5. Pipeline(相比于SDS,加了一个unet_lora来建模后面那一项)
(Wang 等, 2023, p. 6)
四、实验结果
VSD和SDS相关工作的比较
- SDS是VSD的特例
- VSD适用于低CFG Guidance,且灵活

2. text-to-3D
单物体和室内场景都能做:

精度级别的提高是飞跃性的:

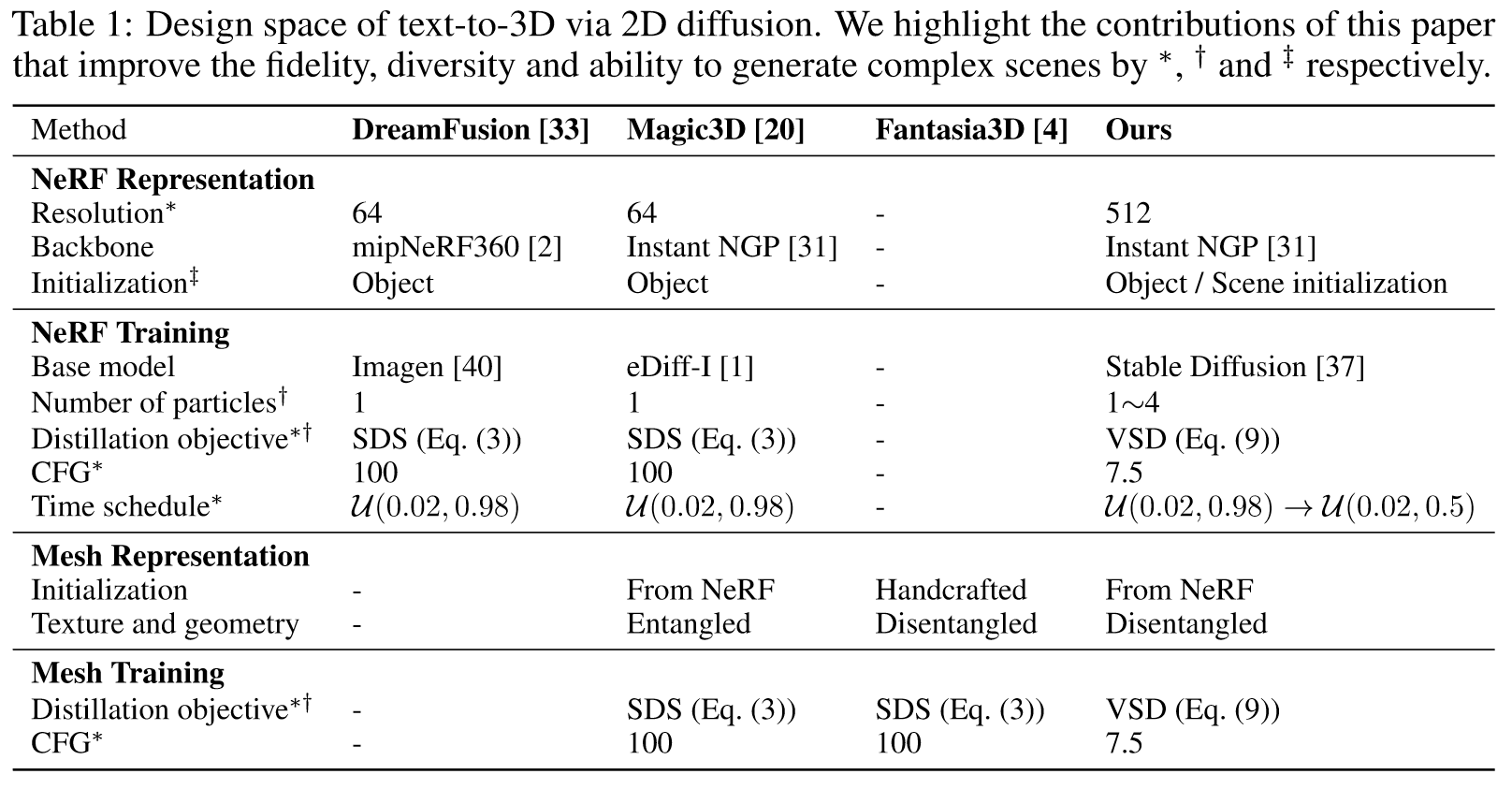
3. Ablation:不同分辨率

五、主要贡献:
对于text-to-3D生成,提出了vsd loss
评价:
- 数学体系是比较完备的
- pipeline很合理,但是其实并不容易做,用lora来实现是一大神秘的成就
- 效果非常非常牛逼
- 笔者跑了它的非官方code,但是不管怎样调参都存在很严重的multiface问题,场景合成结果也不合理,不知道是不是code的问题(但感觉并不是)
- 仅仅是提升了精度的上下限,并没有解决lift 2D to 3D工作存在的一大堆本质问题。但是底层思路是绝对正确的,未来可期。
推荐相关阅读:
- Collaborative Score Distillation for Consistent Visual Synthesis
- DreamFusion: Text-to-3D using 2D Diffusion
- Delta Denoising Score